Modelagem e Arquitetura de Dados
Na DB1, a modelagem e arquitetura de dados desempenham um papel fundamental na organização, desempenho e governança dos dados dentro de um ecossistema de processamento. Adotamos boas práticas que garantem flexibilidade, escalabilidade e confiabilidade, permitindo que os dados sejam consumidos de maneira eficiente e estruturada.
A seguir, detalhamos os principais pilares dessa abordagem, ressaltando que todo o conteúdo apresentado é relativo e pode variar de acordo com as escolhas de tecnologias, modelagens e arquiteturas adotadas. Cada projeto é único e deve ser adaptado às necessidades específicas do negócio, o que pode resultar em diferenças significativas entre os ambientes.
Desenho de Modelos
A modelagem eficiente dos dados é fundamental para garantir não apenas um fluxo de informações bem estruturado e otimizado, mas também para proporcionar flexibilidade e escalabilidade aos sistemas que dependem dessas informações. Ao criar modelos de dados adequados, asseguramos que os dados sejam armazenados de maneira consistente e possam ser acessados e processados com eficiência.
O desenho de modelos de dados envolve a definição de entidades, relacionamentos e estruturas que suportam os requisitos de negócios, garantindo que os dados fluam de maneira lógica e coerente. Um bom modelo de dados facilita não apenas a consulta e o processamento rápidos, mas também a integração de novas fontes de dados, a implementação de transformações complexas e a manutenção de dados de forma sustentável ao longo do tempo.
Documentação
Além disso, um modelo de dados bem estruturado deve ser acompanhado por uma documentação acessível, que descreva claramente como os dados são gerados, transformados e armazenados. A documentação é uma ferramenta essencial para qualquer equipe que precise compreender o fluxo de dados, como parte de práticas de governança de dados e compliance. Ela também facilita a comunicação entre as partes interessadas, além de ser crucial para a manutenção e evolução do sistema ao longo do tempo.
Modelagem
Seguindo boas práticas na modelagem de dados, podemos não apenas otimizar o desempenho do sistema, mas também garantir a qualidade, confiabilidade e integridade dos dados, contribuindo para a tomada de decisões mais informadas e eficientes dentro da organização. Seguimos boas práticas nos seguintes modelos por exemplo:
Modelagem Relacional
Aplicação de normalização para reduzir redundância e garantir integridade e consistência dos dados em bancos SQL como PostgreSQL, MySQL e SQL Server, além de ser útil para explicar o relacionamento entre entidades.
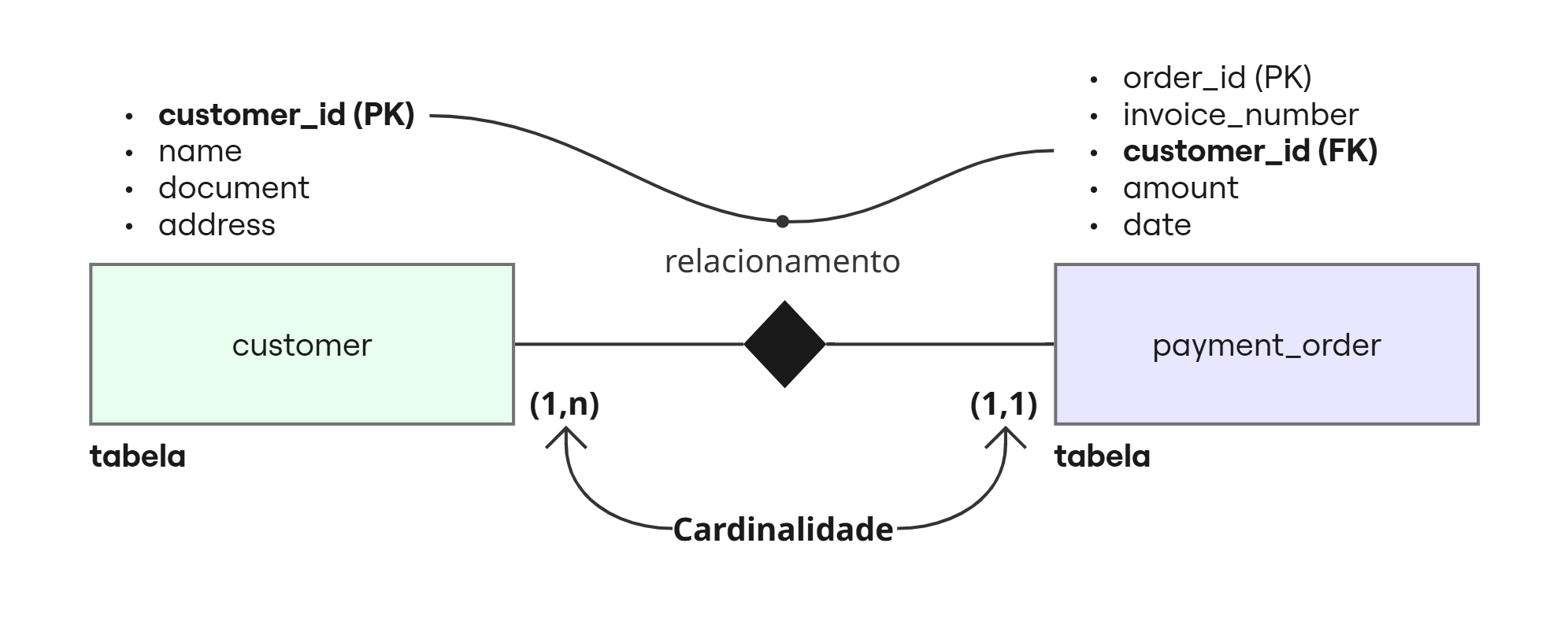
Modelagem Dimensional
Estruturas otimizadas para análise de dados, utilizando conceitos de fato e dimensão, é comum principalmente em bancos de dados OLAP (Online Analytical Processing), onde o foco é facilitar análises rápidas e intuitivas, comum em data warehouses e aplicáveis em Snowflake, BigQuery, Redshift e Databricks.
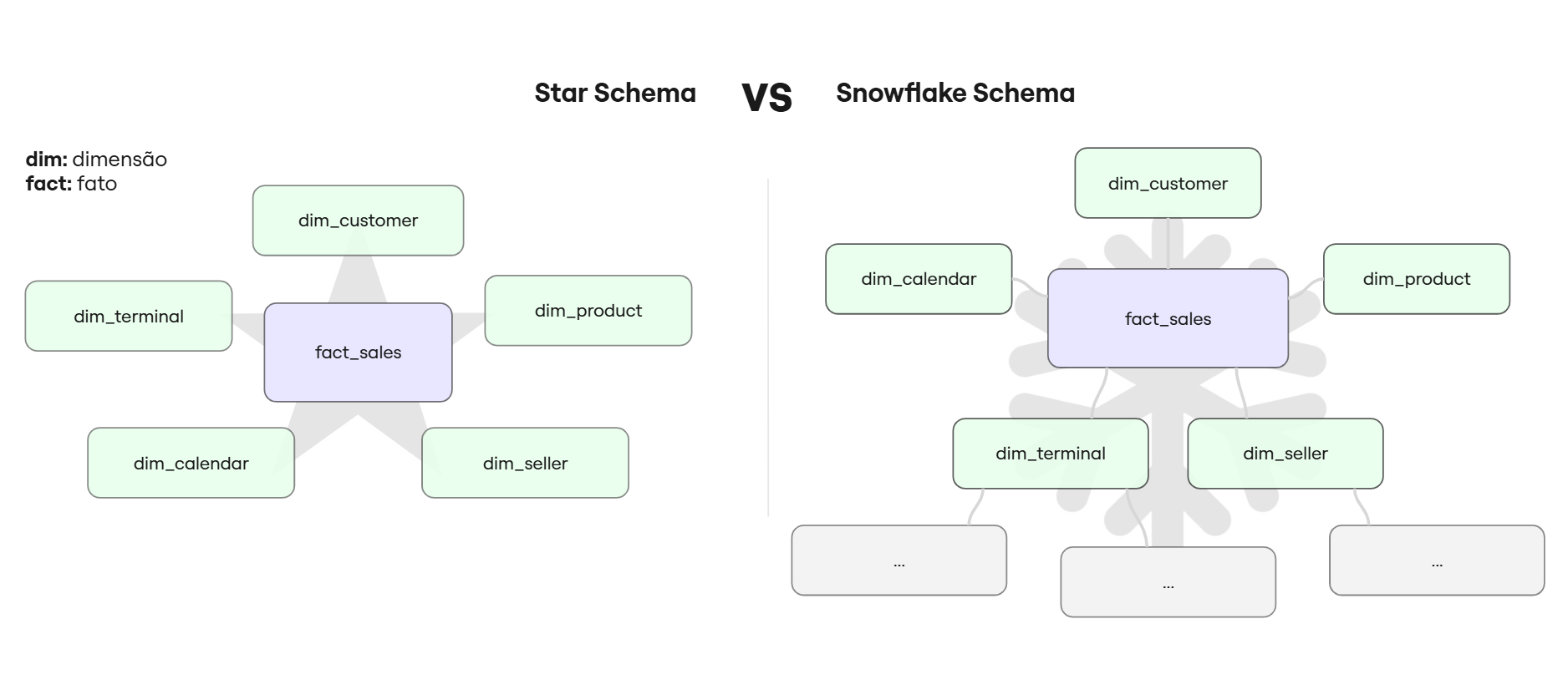
Principais diferenças
| Característica | Modelagem Relacional | Modelagem Dimensional |
|---|---|---|
| Foco | Processamento transacional | Análise de dados |
| Estrutura | Entidades e relacionamentos | Fatos e dimensões |
| Normalização | Alta (3FN ou mais) | Baixa (denormalizada) |
| Performance | Otimizada para escrita | Otimizada para leitura |
| Casos de uso | Sistemas operacionais | Data warehouses / BI |
Modelagem Orientada a Eventos (Event Driven)
Construção de esquemas baseados em eventos, utilizando Kafka, DynamoDB, MongoDB e EventBridge. Você modela os dados a partir do que acontece no sistema — cliques, compras, atualizações, acessos, transferências, etc. — em vez de apenas modelar as entidades envolvidas.
A Modelagem Orientada a Eventos também é muito útil e comum para ingestão de dados em tempo real e possui outras características como:
- Event sourcing para reprocessamento e auditoria.
- Log de eventos Kafka como fonte de verdade.
- Integração com modelos de Machine Learning em tempo real
Modelagem tradicional (orientada a entidades):
{
"usuario": {
"id": 1,
"nome": "João",
"saldo": 100.00
}
}Modelagem orientada a eventos:
[
{
"evento": "criou_conta",
"usuario_id": 1,
"timestamp": "2024-01-01T12:00:00Z"
},
{
"evento": "deposito_realizado",
"usuario_id": 1,
"valor": 100.00,
"timestamp": "2024-01-02T08:30:00Z"
}
]Mais do que uma questão técnica, a modelagem bem estruturada permite que os dados apoiem decisões estratégicas, impulsionem a inovação e sustentem o crescimento do negócio. Na DB1, entendemos que cada projeto é único e que a modelagem de dados deve ser flexível o suficiente para acompanhar a evolução das necessidades do mercado, garantindo sempre a melhor performance e aderência às exigências do negócio.
Camadas de Dados
A organização dos dados em camadas estruturadas permite melhor governança, segurança e otimização do desempenho. Na DB1 buscamos utilizar modelos que facilitam o controle de acessos, a padronização dos processos e a escalabilidade da arquitetura em camadas.
Abordagens de Nomenclatura para Camadas de Dados
Stage, Trusted e Refined
- Stage: Refere-se à camada onde os dados são armazenados logo após a ingestão, sem nenhuma transformação significativa. É como um "raw data" (dados crus), muitas vezes mantidos no formato original e prontos para serem processados.
- Trusted: Nesta camada, os dados são validados, limpos e, se necessário, enriquecidos. O objetivo é garantir que os dados sejam confiáveis e precisos, prontos para ser utilizados por sistemas de análise.
- Refined: A camada refinada envolve transformações mais avançadas, incluindo agregações, modelos de dados e preparação para análises mais detalhadas, com dados que já estão prontos para gerar insights.
Bronze, Silver e Gold (Arquitetura Medalion)
- Bronze: Assim como o stage, representa dados brutos ou semi-processados, muitas vezes sem grandes transformações.
- Silver: Semelhante ao trusted, é a camada onde os dados são limpos, validados e transformados para garantir a qualidade e a consistência, muitas vezes com dados mais estruturados e preparados para análises mais específicas.
- Gold: É a camada final, onde os dados estão prontos para análises de alto nível, visualizações e insights, com transformações avançadas aplicadas, podendo incluir métricas ou dados agregados.
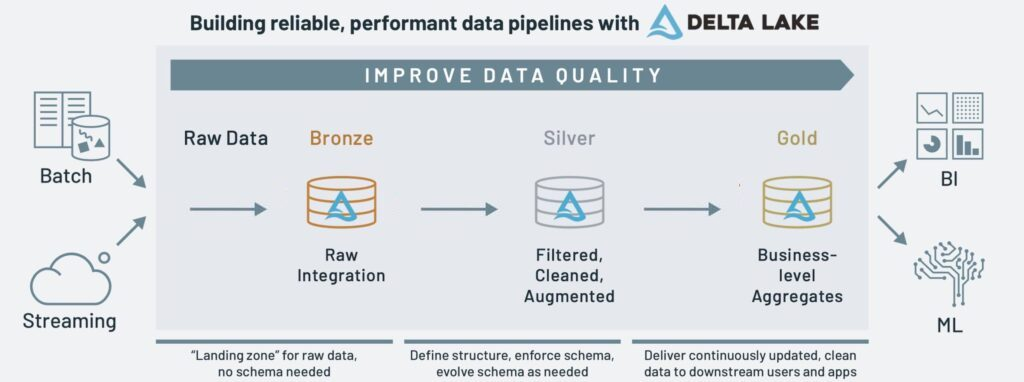
Diferenças principais:
Semântica: A principal diferença é que a abordagem de stage, trusted e refined enfatiza mais o processo de transformação e qualidade dos dados, com foco no ciclo de vida dos dados e sua preparação para uso final. A abordagem bronze, silver e gold é mais associada à evolução do estado dos dados em um processo progressivo de refinamento e preparação para análises.
Nível de abstração: A terminologia bronze, silver e gold tende a ser mais intuitiva quando se trata de visualizar o progresso dos dados de uma maneira mais tangível (do "bronze" como algo bruto até o "gold" como algo refinado). A terminologia stage, trusted e refined foca mais nas camadas de confiança e refinamento.
Em resumo ambas as abordagens têm o mesmo objetivo de estruturar e classificar as camadas de dados, mas a terminologia bronze, silver e gold é mais visual e associada ao conceito de um pipeline de dados progressivo, enquanto stage, trusted e refined pode ser mais aplicada a ambientes que priorizam o controle de qualidade e confiança ao longo do processo de dados. Ambas são eficazes, dependendo do foco do time e da cultura de dados da organização.
Cada camada tem um propósito específico, permitindo maior controle e segurança no fluxo de informações.
Versionamento de Dados
O versionamento de dados assegura a rastreabilidade e a confiabilidade das informações ao longo do tempo. Utilizamos estratégias como controle de snapshots, logs de mudanças e armazenamento de múltiplas versões para garantir integridade e recuperação eficiente. Exemplo de estratégias que abordamos:
- SCD (Slowly Changing Dimensions): Aplicação de estratégias de versionamento para rastreamento de mudanças em bases dimensionais.
- Data Lake Versioning: Utilização de formatos como Delta Lake e Apache Iceberg para versionamento eficiente em ambientes distribuídos.
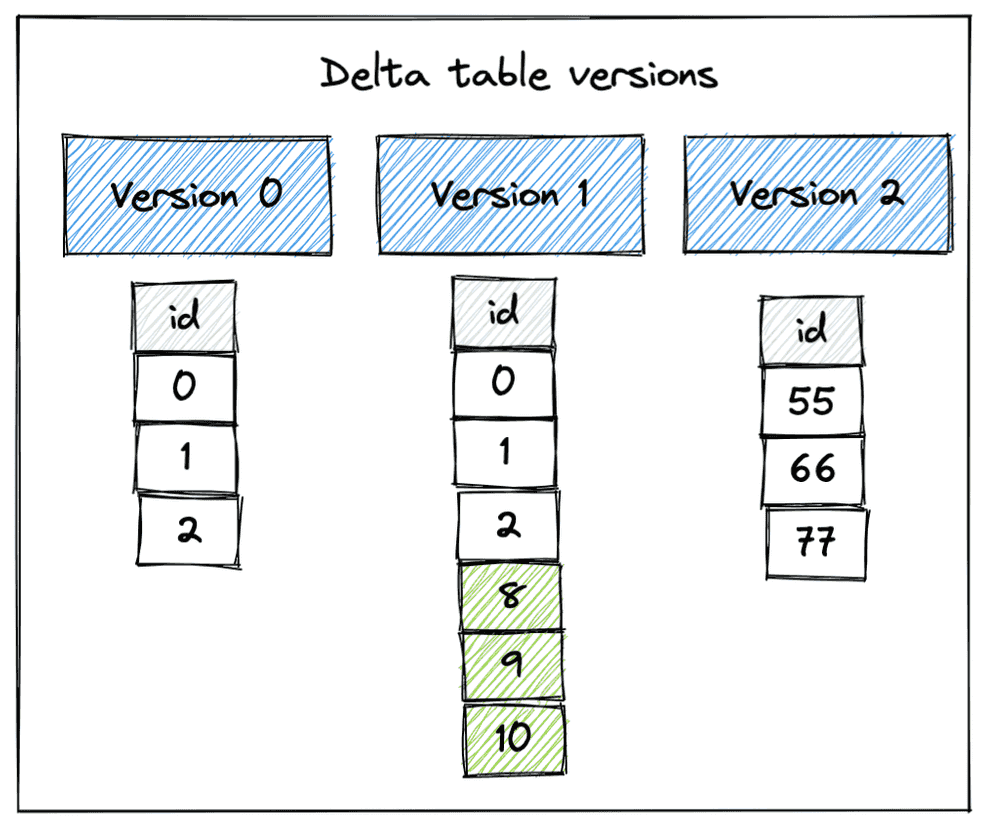
- Time Travel: Recursos nativos de bancos como Snowflake, Delta Lake e BigQuery permitem consultar versões anteriores de um dataset.
- Data Lineage Tools: Ferramentas como dbt Power User(extensão para dbt) ou soluções integradas como Unity Catalog (Databricks), AWS Glue Data Catalog ou DataHub são extremamente úteis para rastreabilidade de uma ou mais entidades relacionadas.
- Auditabilidade vs Observabilidade:
Auditabilidade -> foco em "quem mexeu e quando".
Observabilidade -> foco em "como o dado se comporta, flutuações, anomalias".
Em resumo, o versionamento de dados é essencial para garantir a confiança, rastreabilidade e capacidade de auditoria ao longo do ciclo de vida da informação. Seja por meio de técnicas como SCDs, formatos com suporte a time travel ou ferramentas de data lineage, o objetivo central é possibilitar que as mudanças nos dados sejam compreendidas, controladas e revertidas quando necessário — promovendo maior governança, transparência e segurança na tomada de decisão.
Tipos de Arquiteturas de Dados
Na DB1, adotamos diferentes arquiteturas para atender a variados casos de uso dentro dos nossos projetos. Cada arquitetura é escolhida conforme a necessidade de escalabilidade, desempenho, governança e processamento de dados. Dentre as principais, incluem-se:
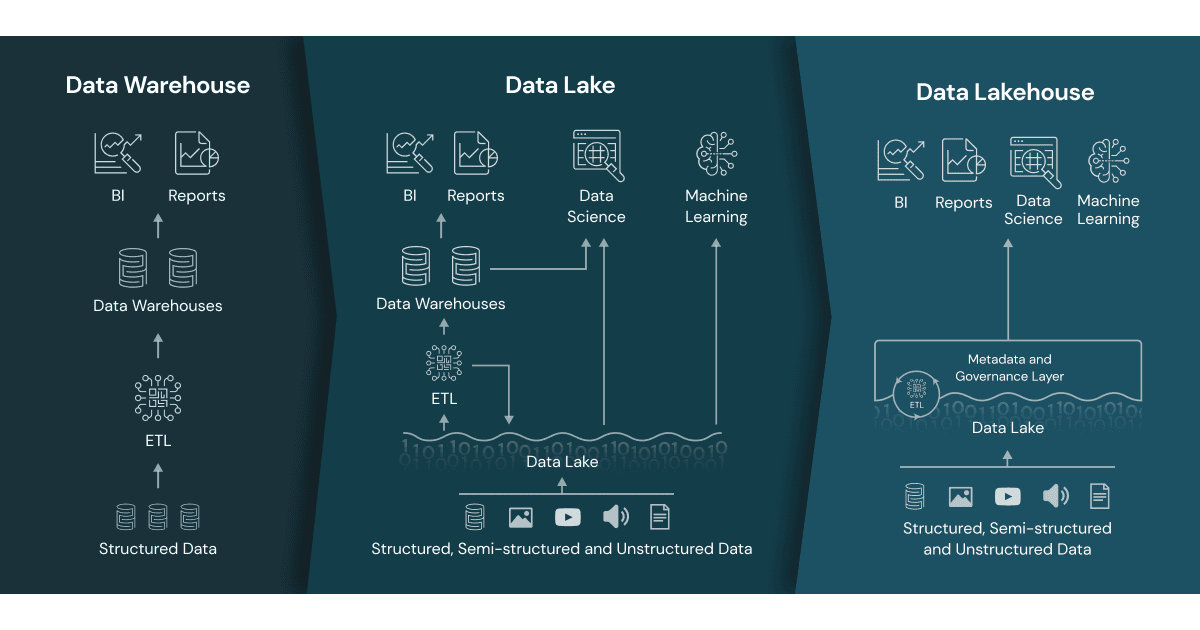
Data Lake
O Data Lake é uma abordagem flexível para armazenamento de dados brutos e processados, capaz de lidar com grandes volumes e múltiplos formatos (estruturados, semiestruturados e não estruturados).
- Características:
- Armazena dados sem necessidade de estruturação prévia;
- Suporte a processamento batch e streaming;
- Integração com ferramentas de Machine Learning e Big Data;
- Exemplos: Amazon S3 + Athena, Azure Data Lake, Google Cloud Storage.
Data Warehouse
O Data Warehouse é um repositório centralizado que armazena dados estruturados de diversas fontes, permitindo análises avançadas e suporte à tomada de decisões.
- Características:
- Modelagem estruturada (ex.: Star Schema, Snowflake Schema);
- Suporte a consultas complexas e analíticas (OLAP);
- Alta confiabilidade e governança;
- Exemplos: Amazon Redshift, Google BigQuery, Snowflake.
Data Lakehouse
O Data Lakehouse combina a flexibilidade de um Data Lake com a estrutura e governança de um Data Warehouse, permitindo análises avançadas em um ambiente unificado.
- Características:
- Suporte a processamento de grandes volumes com consultas analíticas eficientes;
- Governança aprimorada e controle de acesso granular;
- Exemplos: Databricks Delta Lake, Apache Iceberg, Apache Hudi.
Data Mesh
O Data Mesh é uma abordagem descentralizada para gestão de dados, focada em autonomia e escalabilidade organizacional, por se tratar de uma arquitetura moderna, porém complexa, no próximo tópico abordamos mais a fundo os conceitos de Data Mesh separadamente.
- Características:
- Organização baseada em domínios de dados;
- Governança distribuída e padronizada;
- Democratização do acesso aos dados;
- Exemplos: Implementado com ferramentas como Kafka, Snowflake, Databricks, AWS Glue.
Event-Driven Architecture (EDA)
A Arquitetura Orientada a Eventos (EDA) permite a comunicação assíncrona entre sistemas, garantindo escalabilidade e processamento em tempo real.
- Características:
- Processamento de eventos em tempo real;
- Suporte a escalabilidade horizontal;
- Ideal para sistemas distribuídos e microservices;
- Exemplos: Apache Kafka, AWS Kinesis, Google Pub/Sub.
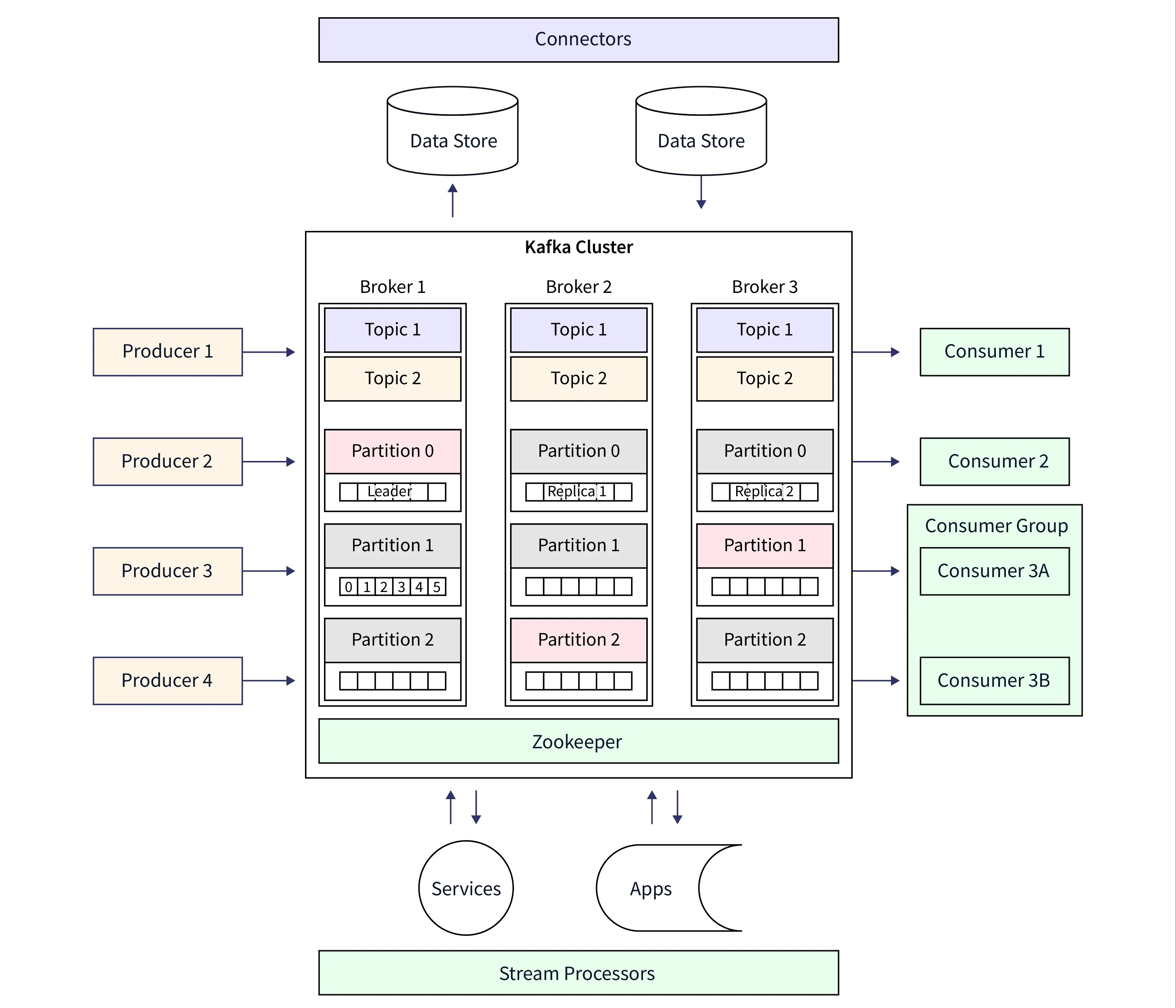
Producer (Produtor): É o componente que gera e publica eventos para um sistema de mensageria (como Kafka, RabbitMQ ou SQS). Um produtor pode ser um serviço, aplicação ou sensor que emite dados para serem consumidos posteriormente.
Consumer (Consumidor): É o componente que escuta e processa os eventos gerados pelo producer. Ele pode armazenar, transformar ou executar ações com base nos dados recebidos.
Na arquitetura orientada a eventos, producers geram eventos que são consumidos de forma assíncrona por consumers, promovendo desacoplamento entre os sistemas, escalabilidade e reatividade em tempo real.
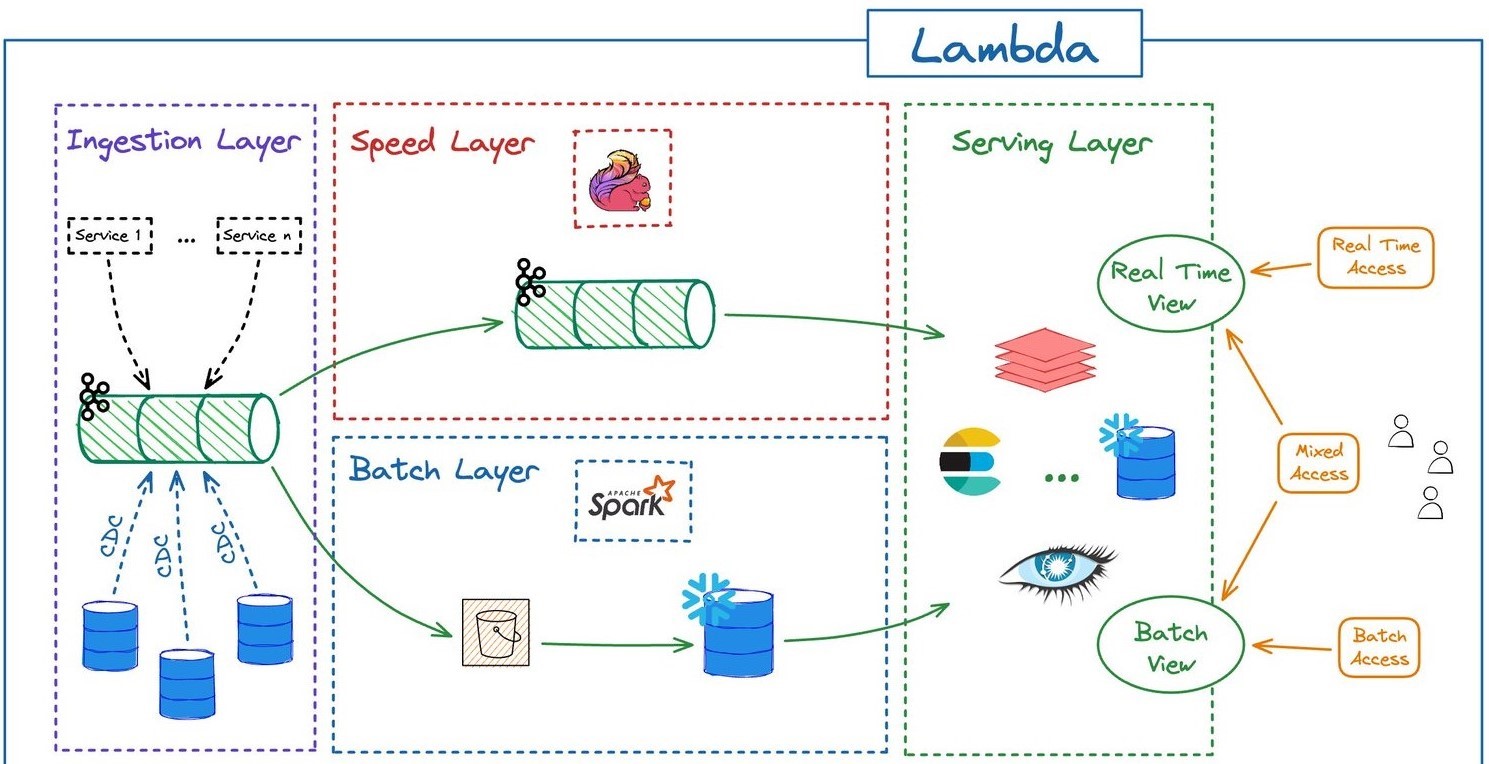
Lambda Architecture
A Arquitetura Lambda combina processamento batch e em tempo real, garantindo baixa latência e consistência de dados.
- Características:
- Camada de velocidade para processamento em tempo real;
- Camada de batch para reprocessamento e correção de dados;
- Unificação das camadas para consultas consistentes;
- Exemplos: Apache Spark, Hadoop, Kafka, AWS Lambda.
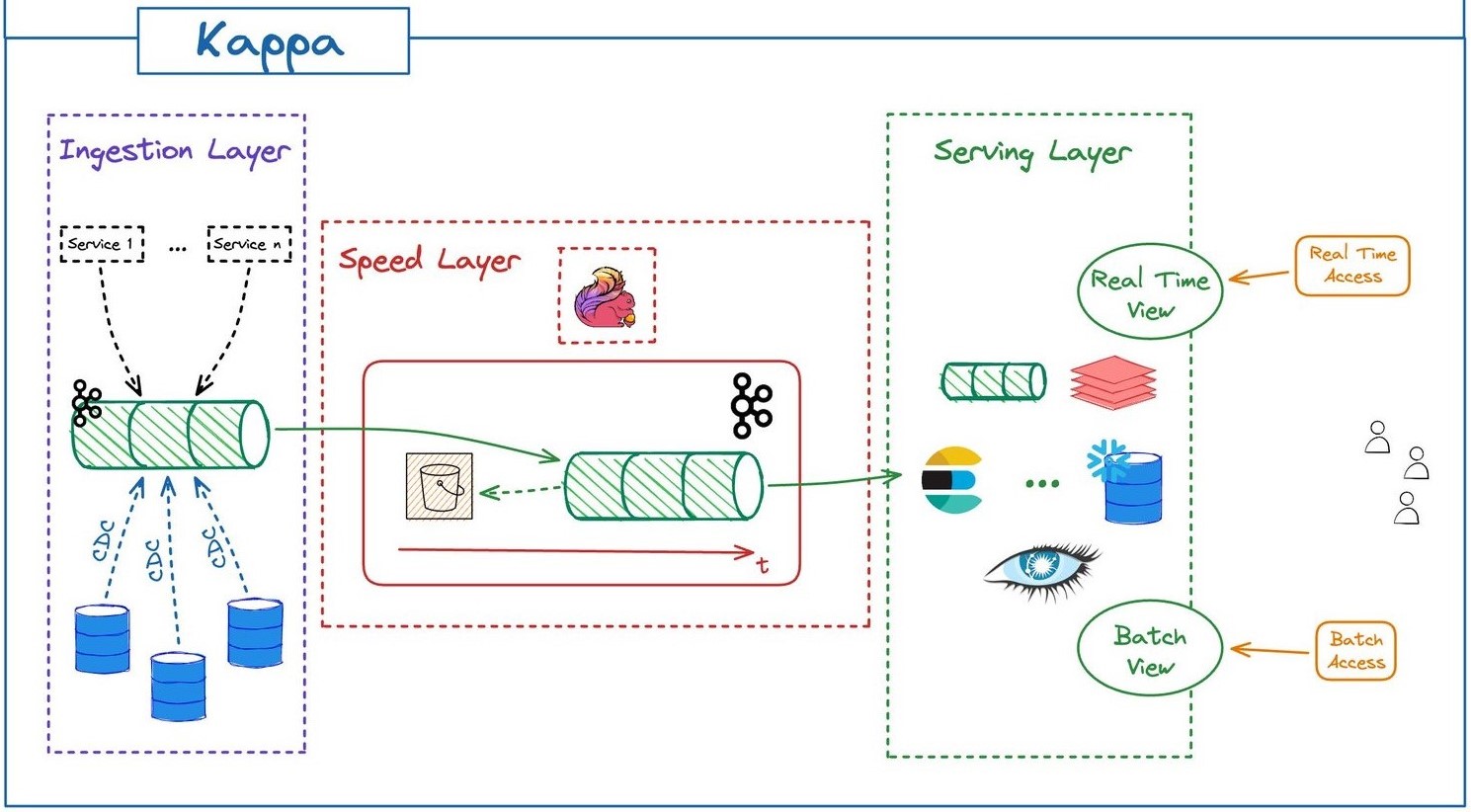
Kappa Architecture
A Arquitetura Kappa simplifica o processamento de dados ao utilizar um único fluxo contínuo de eventos, eliminando a necessidade de uma camada batch.
- Características:
- Processamento contínuo e unificado;
- Redução da complexidade operacional;
- Ideal para sistemas que priorizam eventos em tempo real;
- Exemplos: Apache Flink, Kafka Streams, Apache Samza.
Comparativo entre os tipos de arquitetura:
| Arquitetura | Performance | Custo | Flexibilidade | Governança | Tempo Real |
|---|---|---|---|---|---|
| Data Warehouse | Alta | Alto | Baixa | Alta | Não |
| Data Lake | Média | Baixo | Alta | Média | Parcial |
| Lakehouse | Alta | Médio | Alta | Alta | Sim |
| Data Mesh | Variável | Variável | Alta | Descentralizada | Sim |
Cada uma dessas arquiteturas tem um papel fundamental na estratégia de dados de uma organização, e a escolha depende dos requisitos de escalabilidade, latência, governança e casos de uso específicos.
Arquitetura Data Mesh
O Data Mesh representa uma abordagem inovadora e descentralizada para o gerenciamento de dados em organizações que lidam com múltiplos domínios de dados. Na DB1 buscamos uma abordagens diferente das tradicionais centralizadas, onde todos os dados são geridos em um único ponto, o Data Mesh foca na distribuição da responsabilidade sobre os dados, tratando-os como produtos dentro de diferentes domínios de negócio.
Essa abordagem tem como objetivo a escalabilidade, agilidade e autonomia das equipes de dados, permitindo que cada domínio trate seus dados de forma independente e alinhada às necessidades de seu contexto específico, ao mesmo tempo em que promove a governança federada para garantir consistência e compliance.
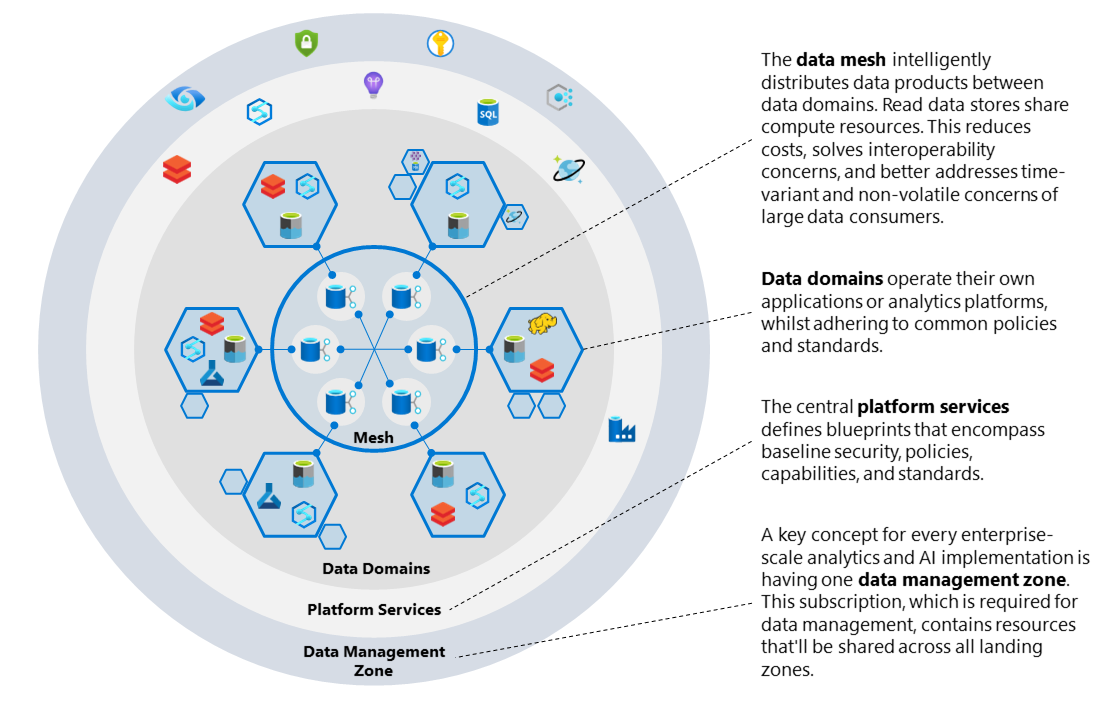
Princípios do Data Mesh
A implementação do Data Mesh se baseia em quatro princípios fundamentais:
Domínios de Dados Descentralizados
Em vez de centralizar a responsabilidade dos dados em uma única equipe ou sistema, o Data Mesh distribui a gestão dos dados para os domínios de negócio. Cada domínio é responsável por gerenciar seus próprios dados de maneira autônoma, garantindo que esses dados atendam às necessidades de seu contexto específico.
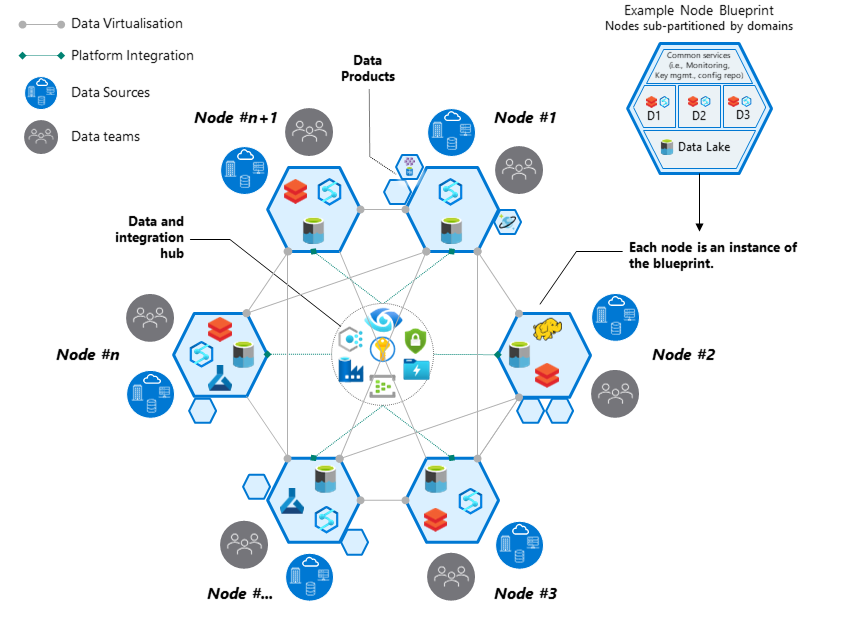
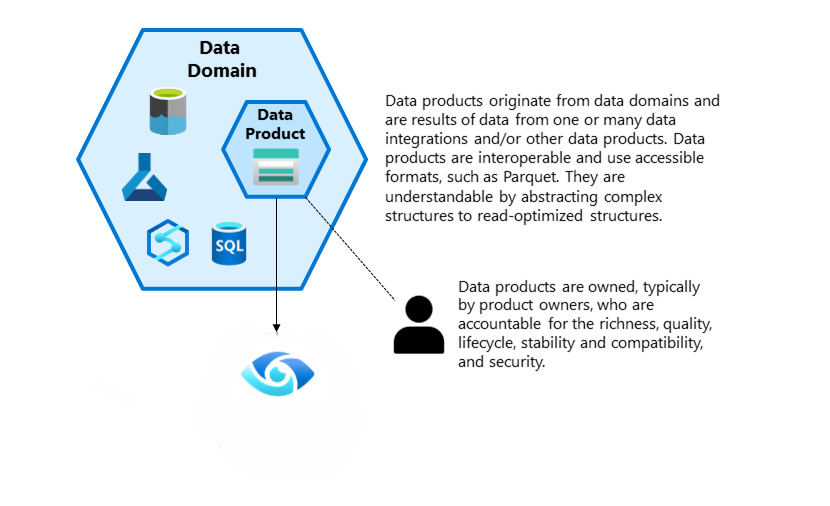
Dados como Produto
Cada domínio deve tratar os dados como produtos: isso significa que as equipes são responsáveis pela criação, manutenção e entrega de dados de qualidade para outras partes da organização. A ideia é que os dados sejam fornecidos de forma que sejam facilmente consumíveis por outros usuários e sistemas, com alta qualidade e acessibilidade.
Plataformas de Autoatendimento
O Data Mesh enfatiza a criação de plataformas de autoatendimento, permitindo que as equipes acessem e integrem dados sem depender de uma infraestrutura centralizada. Ferramentas e frameworks são desenvolvidos para facilitar a ingestão, transformação e análise de dados, permitindo que as equipes de diferentes domínios se conectem de maneira simples e eficiente.
Governança Federada
Embora o Data Mesh distribua a responsabilidade dos dados entre os domínios, a governança deve ser federada, ou seja, a governança é compartilhada entre os domínios, com diretrizes e políticas de controle e qualidade sendo aplicadas de maneira consistente em toda a organização. Isso garante que todos os dados sigam os mesmos princípios de qualidade, segurança e conformidade.
Benefícios do Data Mesh
Escalabilidade
Com o Data Mesh, as organizações conseguem escalar suas operações de dados de forma eficiente, adaptando-se às necessidades de diferentes domínios e sem sobrecarregar uma infraestrutura centralizada. Isso resulta em uma capacidade aumentada de lidar com grandes volumes de dados sem comprometimento de desempenho.
Responsabilidade Clara pelos Dados
A descentralização garante que cada equipe seja a responsável pelos dados que gerencia. Isso leva a um aumento na qualidade dos dados, uma vez que as equipes estão mais alinhadas com os requisitos específicos dos dados de seu domínio e com o impacto direto que eles causam nas operações de negócio.
Maior Agilidade
As equipes de domínio podem inovar mais rapidamente, pois não precisam depender de uma equipe centralizada para acessar ou transformar os dados. Isso aumenta a capacidade de adaptação às mudanças rápidas no negócio e permite um ciclo de desenvolvimento mais ágil.
Desafios do Data Mesh
Complexidade na Implementação
Implementar o Data Mesh pode ser desafiador, especialmente em organizações grandes, onde a integração de múltiplos domínios de dados pode exigir um esforço significativo para coordenar a implementação das práticas de governança, plataformas de autoatendimento e interconexão de sistemas.
Manutenção de Governança e Compliance
A governança federada, embora potente, pode ser difícil de implementar e manter. Garantir a conformidade com regulamentações e políticas de segurança sem prejudicar a flexibilidade das equipes pode ser uma tarefa complexa, especialmente quando se lida com múltiplos domínios e tecnologias.
Arquiteturas e Ferramentas para Data Mesh
O sucesso do Data Mesh depende da escolha correta de arquiteturas e ferramentas. Algumas tecnologias que podem ser utilizadas para implementar um Data Mesh incluem:
- Kubernetes: Para orquestrar a execução de pipelines de dados de forma distribuída e escalável.
- Apache Kafka: Como sistema de mensageria para facilitar a troca de dados entre diferentes domínios e serviços.
- dbt: Para modelagem e transformação de dados em uma abordagem modular e reutilizável.
- Apache Airflow: Para orquestrar e monitorar pipelines de dados distribuídos.
- Plataformas em Nuvem (AWS, Azure, GCP): Para suportar a infraestrutura distribuída e garantir o armazenamento e processamento de dados de forma escalável.
Essas ferramentas permitem que cada domínio gerencie seus próprios dados de maneira independente, ao mesmo tempo que possibilitam a integração e governança eficiente dos dados em toda a organização.
O Data Mesh oferece uma abordagem inovadora e escalável para organizações que enfrentam desafios relacionados ao gerenciamento de grandes volumes de dados em múltiplos domínios. Embora seja um modelo mais complexo do que as arquiteturas tradicionais, seus benefícios, como escalabilidade, autonomia das equipes e agilidade, fazem com que seja uma opção atraente para empresas que buscam evoluir em suas estratégias de dados.
Data Contracts
Data Contracts, ou "contratos de dados", são acordos entre quem produz e quem consome informações dentro de uma empresa. Eles servem para garantir que os dados sejam entregues da forma certa, no momento certo, sem causar problemas para outras pessoas ou sistemas que dependem dessas informações.
Por que isso é importante?
Quando diferentes equipes usam os mesmos dados, é essencial que todos estejam falando a mesma "língua". Os Data Contracts ajudam a garantir isso, com base em três pilares principais:
- Especificação Clara: define exatamente como os dados devem ser, como tipos, formatos, nomes e regras.
- Validação Automática: usamos ferramentas como Great Expectations e dbt tests para checar automaticamente se os dados estão corretos.
- Versionamento Seguro: quando os dados mudam, isso é feito de forma controlada, sem prejudicar quem já usa os dados antigos.
Na DB1, usamos Data Contracts para garantir um alinhamento claro entre as equipes que pedem informações e as que desenvolvem as soluções. Isso evita mal-entendidos, retrabalhos e problemas em cadeia.
Para que as informações estejam sempre disponíveis, confiáveis e prontas para gerar valor, seguimos boas práticas e modernas de modelagem e arquitetura, essas práticas fazem parte da nossa jornada para transformar dados em valor real para o negócio — com segurança, escalabilidade e colaboração entre todas as áreas envolvidas.
Créditos: