Governança de Dados
Na DB1, governança de dados não é apenas uma prática – é a base para garantir que nossas decisões sejam confiáveis, nossas análises sejam precisas e nossas operações sejam eficientes.
Adotamos um modelo unificado de governança que permite padronizar a forma como lidamos com dados em diferentes projetos e times, evitando inconsistências, retrabalho e riscos estratégicos. Com base em frameworks consolidados, como o DMBOK (Data Management Body of Knowledge) e o modelo de maturidade do Gartner, buscamos sempre evoluir nossos processos, monitorar nossa maturidade e garantir que segurança, qualidade e confiabilidade estejam no centro de tudo o que fazemos com dados.
Padrões e Consistência
Um dos principais desafios ao escalar soluções de dados está em manter padrões consistentes entre diferentes projetos, squads e contextos. Padrão, nesse caso, não significa engessar a entrega — mas garantir que todos falem a mesma linguagem e sigam uma lógica comum, promovendo interoperabilidade e sustentabilidade técnica no longo prazo.
Na prática, isso se traduz em:
- Modelagem de Dados: Utilizamos convenções de nomenclatura, padronização de tipos e estruturas que facilitam a leitura, entendimento e manutenção das bases.
- Documentação Técnica: Todo pipeline ou processo deve conter documentação clara e atualizada, garantindo que qualquer pessoa consiga entender o que está sendo feito e por quê.
- Templates de Código e Estrutura: Definimos modelos reutilizáveis para desenvolvimento de pipelines, testes e provisionamento de infraestrutura, acelerando entregas e reduzindo erros.
- Padronização de Logs e Monitoramento: Garantimos que os logs sigam uma estrutura comum, facilitando a rastreabilidade, depuração e observabilidade dos pipelines.
- Governança Semântica: Padronizamos conceitos e métricas de negócio entre os times para evitar interpretações ambíguas sobre os dados.
Padrões não são burocracia — são aliados na eficiência, segurança e confiabilidade dos nossos dados. Manter consistência permite que engenheiros transitem entre projetos sem precisar “reaprender” como tudo funciona, além de facilitar auditorias, integrações e evolução contínua da stack.
Validação e Testes
A confiabilidade de qualquer produto de dados começa pela validação automatizada. Dados imprecisos ou corrompidos impactam diretamente a qualidade das análises e podem comprometer decisões críticas. Por isso, garantir a integridade dos dados através de testes estruturados é uma etapa essencial no nosso processo de desenvolvimento.
Na prática, implementamos testes automatizados em diferentes níveis das pipelines, com foco em três pilares principais:
- Qualidade dos Dados: Validamos se os dados atendem às regras de negócio, formatos esperados, faixas de valores e se estão livres de duplicações ou campos nulos indevidos.
- Integridade: Garantimos que as relações entre tabelas, chaves primárias/estrangeiras, e outras dependências estruturais estejam preservadas ao longo das transformações.
- Confiabilidade: Testamos se os dados são consistentes ao longo do tempo, e se refletem corretamente as mudanças que ocorrem nas fontes.
Utilizamos ferramentas como Great Expectations, dbt tests, pytest, entre outras, que nos permitem definir expectativas, validar resultados e monitorar falhas de forma contínua.
Além dos testes unitários e de integração, também aplicamos validações ao final das pipelines, atuando como uma barreira de segurança antes que os dados cheguem ao ambiente de consumo.
Manter uma base sólida de testes nos permite:
- Reduzir erros em produção;
- Facilitar a manutenção e evolução das pipelines;
- Garantir transparência e confiança nas entregas de dados;
- Evitar retrabalho e análises equivocadas.
Testar dados não é um "plus", é parte do nosso compromisso com a entrega de produtos de dados robustos, escaláveis e confiáveis.
Gestão de Acessos
A gestão de acessos é um dos pilares fundamentais da Governança de Dados na DB1, pois garante que os dados certos estejam acessíveis apenas para as pessoas certas, no momento certo. Isso não é apenas uma questão de segurança — é também sobre responsabilidade, conformidade e eficiência operacional.
Aplicamos o princípio do menor privilégio, onde cada pessoa ou time tem acesso apenas ao que é essencial para realizar suas atividades. Isso reduz riscos de vazamentos, elimina exposições desnecessárias de dados sensíveis e contribui para o cumprimento de normas como a LGPD.
Para facilitar a visualização dessa estrutura de acesso, utilizamos um modelo de mapeamento por função, como no exemplo abaixo:
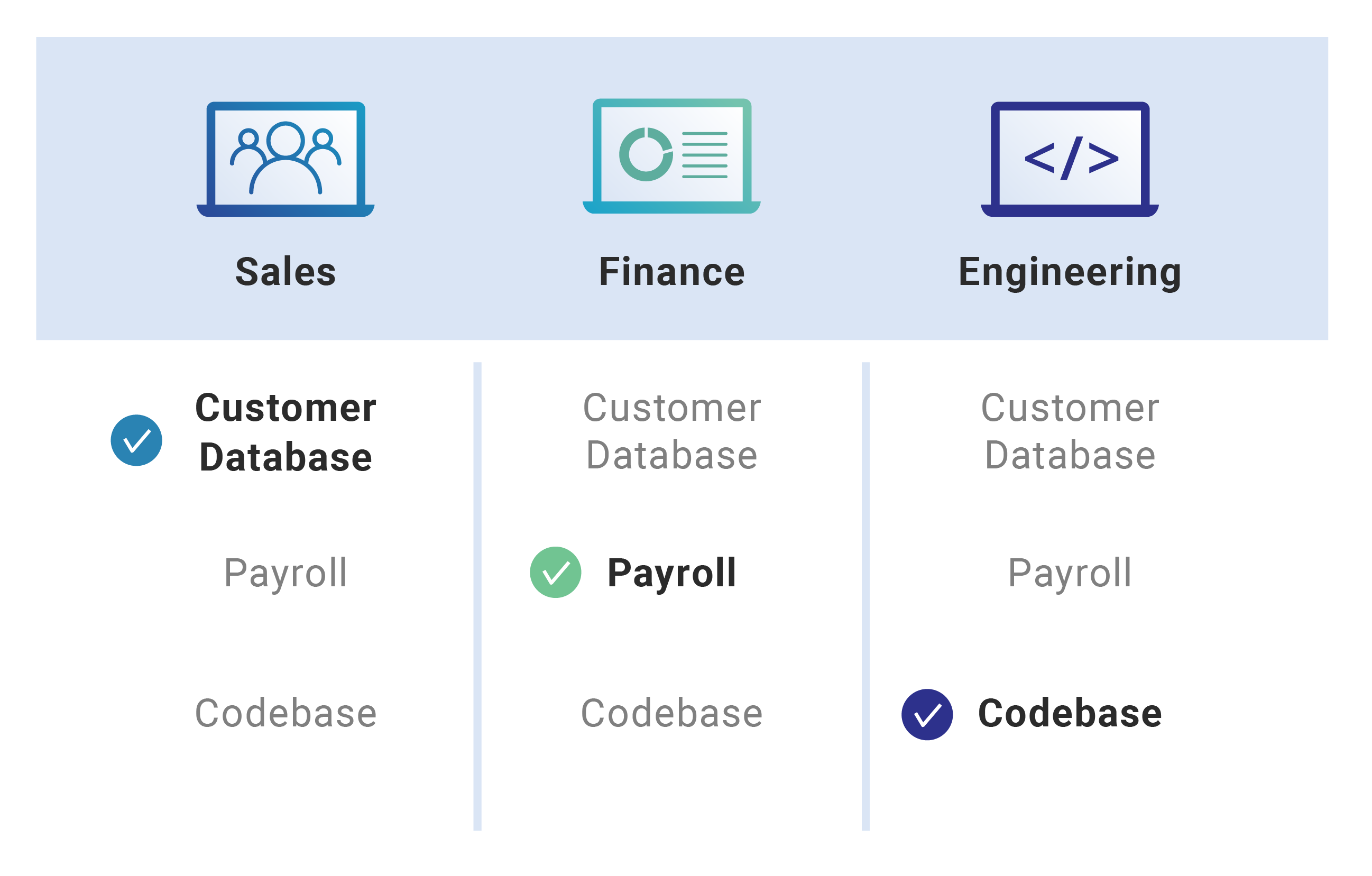
Nesse exemplo, cada área tem acesso apenas aos recursos diretamente relacionados às suas responsabilidades:
- Sales (Vendas): acesso ao banco de dados de clientes.
- Finance (Financeiro): acesso à folha de pagamento.
- Engineering (Engenharia): acesso ao repositório de código.
Essa abordagem é igualmente aplicada na nossa área de dados, onde diferentes perfis têm acessos segmentados, como por exemplo:
| Perfil | Acesso a Tabelas de Negócio | Acesso a Pipelines e Infra | Acesso a Logs e Políticas |
|---|---|---|---|
| Data Analysts | ✅ Leitura | ❌ | ❌ |
| Data Engineers | ❌ | ✅ Desenvolvimento | ❌ |
| Data Governance | ✅ Leitura | ❌ | ✅ Completo |
Além disso, utilizamos ferramentas como IAM e Azure Purview (dependendo da stack do projeto) para gerenciar permissões de forma centralizada, com trilhas de auditoria e revisões periódicas.
Adotamos controles como:
- Revisões periódicas de acesso;
- Solicitação e aprovação via workflow (ex: Jira, ServiceNow);
- Auditoria ativa de logs e alterações;
- Integração com diretórios corporativos (AD/SSO).
Gestão de acessos eficiente não é sobre limitar o trabalho das pessoas — é sobre criar um ambiente de confiança, rastreabilidade e conformidade, sem comprometer a agilidade. É assim que protegemos nossos dados e fortalecemos nossa cultura de responsabilidade compartilhada.
Gerenciamento de Metadados
O Gerenciamento de Metadados desempenha um papel fundamental na Governança de Dados da DB1, garantindo que os dados possuam significado claro, contexto bem definido e uso padronizado em toda a organização. Definir taxonomias e glossários de dados permite que diferentes times trabalhem de forma alinhada, minimizando ambiguidades e otimizando a interoperabilidade entre sistemas e processos.
Taxonomias e Classificação de Dados
A definição de taxonomias padronizadas é essencial para organizar e classificar os dados de maneira hierárquica, possibilitando uma navegação estruturada e intuitiva pelas informações disponíveis. Utilizamos abordagens como:
- Classificação por Domínio de Negócio: Agrupamento de dados por áreas como Vendas, Financeiro, Marketing e Engenharia.
- Categorização por Sensibilidade: Dados classificados como públicos, internos, confidenciais ou sensíveis, seguindo diretrizes da LGPD e GDPR.
- Hierarquia de Entidades: Estruturas que definem relações entre entidades como Clientes, Produtos e Transações, promovendo consistência no uso dos dados.
Essa abordagem padronizada evita ambiguidades e facilita a descoberta, reutilização e controle dos dados em diferentes contextos de análise.
Glossário de Dados e Semântica Padronizada
Para garantir que todos os times falem a mesma linguagem, mantemos um Glossário de Dados Corporativo, documentando de forma clara os principais termos, métricas e definições utilizadas na organização. Esse repositório centralizado permite que qualquer colaborador compreenda o significado, origem e regras de uso dos dados.
O glossário inclui:
- Nome do Campo: Exemplo:
customer_id. - Descrição: Identificador único de um cliente na base de dados.
- Origem: Base extraída do sistema CRM.
- Regra de Validação: Deve ser um valor numérico único e não nulo.
- Relacionamento: Ligado à tabela de
Pedidosvia chave estrangeiracustomer_id.
Ferramentas como Data Catalogs (ex: AWS Glue Data Catalog, Google Data Catalog, Alation, Collibra) são utilizadas para manter o glossário atualizado e acessível.
Benefícios do Gerenciamento de Metadados
Adotar uma estratégia estruturada de gerenciamento de metadados traz vários benefícios:
- Melhoria na Qualidade dos Dados: Reduz ambiguidades e erros causados por interpretações divergentes.
- Maior Eficiência Operacional: Facilita a descoberta e reutilização de dados, reduzindo tempo gasto na busca por informações.
- Facilidade de Auditoria e Compliance: Proporciona trilhas de rastreabilidade e conformidade com normas regulatórias.
- Interoperabilidade: Permite a integração fluida entre sistemas e times.
Na DB1, a gestão eficiente de metadados é parte essencial da governança de dados, garantindo clareza, padronização e confiança em nossas análises e decisões estratégicas.
Data Mart
Um Data Mart é um subconjunto especializado de um data warehouse, projetado para atender às necessidades específicas de um departamento ou área de negócio dentro de uma organização, como vendas, finanças ou marketing.
Ele contém dados focados e relevantes para um grupo específico de usuários, facilitando análises e relatórios direcionados.
Benefícios do Data Mart
Acesso Rápido a Informações
Por conter um volume menor e mais específico de dados, os usuários podem acessar e analisar informações com maior rapidez, melhorando a eficiência na tomada de decisões.Implementação Simplificada
A criação de um data mart é geralmente mais rápida e menos complexa do que a de um data warehouse completo, permitindo que as organizações atendam rapidamente às necessidades de informações de departamentos específicos.Custo Reduzido
Devido ao seu escopo mais limitado, os data marts podem ser implementados com um investimento menor em comparação com data warehouses corporativos abrangentes.
Tipos de Data Mart
Dependente
Derivado de um data warehouse existente, extraindo um subconjunto de dados para atender a necessidades específicas de um departamento.Independente
Criado diretamente a partir de fontes de dados operacionais, sem depender de um data warehouse central.Híbrido
Combina dados de um data warehouse e de sistemas operacionais, oferecendo flexibilidade na obtenção de informações relevantes.
Data Mart e Governança de Dados
A implementação de data marts deve estar alinhada às práticas de governança de dados da organização para garantir a qualidade, segurança e consistência das informações.
Isso inclui a definição clara de políticas de acesso, garantindo que apenas usuários autorizados possam visualizar ou manipular os dados, e a aplicação de padrões de qualidade para assegurar a precisão e integridade das informações armazenadas.
Além disso, a documentação detalhada dos metadados é essencial para manter a clareza sobre a origem, transformação e uso dos dados dentro do data mart, facilitando auditorias e promovendo a transparência nas operações de dados.
A DB1 ao integrar data marts com as diretrizes de governança de dados nos projetos, as organizações podem aproveitar os benefícios de análises especializadas sem comprometer a integridade e a conformidade dos dados corporativos.
Observabilidade e Monitoramento
A Observabilidade e Monitoramento são essenciais para garantir que os sistemas de dados operem de maneira confiável, identificando anomalias rapidamente, prevenindo falhas e assegurando a conformidade com os SLAs de disponibilidade. Na DB1, implementamos práticas robustas de monitoramento para garantir a estabilidade e a previsibilidade dos processos de dados.
Métricas e Indicadores de Performance
Monitoramos continuamente indicadores-chave para avaliar a saúde das nossas pipelines e infraestrutura de dados. Entre as métricas mais relevantes, destacamos:
- Latência de Processamento: Tempo médio para ingestão, transformação e carga dos dados.
- Taxa de Erros: Percentual de falhas em execuções de pipelines e consultas.
- Disponibilidade: Tempo de uptime dos serviços e cumprimento dos SLAs.
- Consumo de Recursos: Utilização de CPU, memória e armazenamento em serviços críticos.
- Qualidade dos Dados: Análises sobre volumes inesperados, anomalias estatísticas e conformidade com regras de validação.
Essas métricas são essenciais para antecipar problemas e garantir que os processos funcionem de forma previsível e eficiente.
Ferramentas de Monitoramento
Utilizamos um stack de observabilidade integrada para coletar, armazenar e analisar métricas em tempo real. Entre as ferramentas aplicadas, destacam-se:
- Prometheus & Grafana: Coleta e visualização de métricas para serviços e pipelines.
- ELK Stack (Elasticsearch, Logstash, Kibana): Monitoramento centralizado de logs.
- AWS CloudWatch / Azure Monitor: Observabilidade nativa para serviços em nuvem.
- OpenTelemetry: Padrão aberto para rastreamento distribuído.
A implementação de um pipeline de monitoramento permite a identificação proativa de falhas, minimizando impactos e acelerando a resolução de incidentes.
Alertas e Resolução de Incidentes
Criamos mecanismos automatizados para detecção e resposta a falhas, garantindo rápida atuação em caso de problemas críticos. Para isso, utilizamos:
- Alertas em Tempo Real: Notificações via Slack, Team ou e-mail ao detectar anomalias.
- Automação de Respostas: Execução de ações corretivas automáticas para falhas previsíveis.
- Análise de Causa Raiz: Logs e rastreamento para entender e corrigir problemas sistêmicos.
A combinação de monitoramento contínuo, métricas bem definidas e resposta ágil permite manter um ambiente de dados altamente disponível, confiável e seguro, alinhado às melhores práticas de governança na DB1.
Por fim, a Governança de Dados na DB1 é um pilar essencial para garantir segurança, qualidade e confiabilidade no uso dos dados. Adotamos um modelo padronizado baseado em frameworks consolidados, como DMBOK e Gartner, promovendo consistência entre projetos e equipes.
Nosso foco está na padronização, validação e gestão de acessos, garantindo que os dados sejam precisos e acessíveis apenas para as pessoas certas. Implementamos testes automatizados, controle de metadados e monitoramento contínuo, reduzindo erros e fortalecendo a rastreabilidade.
Ao integrar processos robustos e ferramentas especializadas, asseguramos que nossos dados sustentem decisões estratégicas e operacionais de forma confiável e eficiente.
Créditos: