Segurança e Compliance
Na DB1, a Segurança e Compliance são pilares essenciais que complementam a Governança de Dados, garantindo não apenas a qualidade e a usabilidade dos dados, mas também sua proteção, integridade e conformidade com as regulamentações vigentes. Em um cenário onde os dados são ativos estratégicos, assegurar que sejam manuseados de forma segura e ética é fundamental para manter a confiança dos nossos clientes, parceiros e colaboradores, além de mitigar riscos legais e operacionais.
Adotamos uma abordagem proativa e integrada para a segurança da informação e conformidade, alinhando nossas práticas com normas reconhecidas como a LGPD (Lei Geral de Proteção de Dados) e o GDPR (General Data Protection Regulation). Isso envolve a implementação de controles técnicos e processos organizacionais robustos em todo o ciclo de vida dos dados.
Métodos de Segurança e Proteção de Dados
A proteção de dados sensíveis é uma prioridade máxima. Utilizamos técnicas de Mascaramento (Masking), Criptografia (Encryption) e Hashing para garantir que informações confidenciais, como dados pessoais identificáveis (PII), informações financeiras ou segredos comerciais, sejam protegidas contra acesso não autorizado, tanto em repouso quanto em trânsito.
Mascaramento de Dados
Aplicamos técnicas como substituição, embaralhamento (shuffling) ou anulação (nulling) para ocultar dados originais em ambientes não produtivos (desenvolvimento, testes, homologação). Isso permite que as equipes trabalhem com estruturas de dados realistas sem expor informações sensíveis, garantindo conformidade com a LGPD e GDPR no que diz respeito à minimização e proteção de dados.
Tabela 1: Dados Originais (Não Mascarados)
Estes são exemplos de dados brutos, contendo informações pessoais identificáveis (PII) e sensíveis.
| ID Cliente | Nome Completo | CPF | Telefone | Salário | |
|---|---|---|---|---|---|
| 101 | Maria Silva | 123.456.789-00 | maria.silva@email.com | (44) 99999-1111 | R$ 5.000,00 |
| 102 | João Pereira | 987.654.321-99 | joao.p@provedor.net | (11) 98888-2222 | R$ 7.500,00 |
| 103 | Ana Costa | 111.222.333-44 | ana.costa@exemplo.org | (21) 97777-3333 | R$ 4.200,00 |
Tabela 2: Dados Mascarados
A mesma tabela após aplicar técnicas de mascaramento. Note como diferentes campos usam métodos distintos (parcial, substituição, remoção) para proteger a privacidade, mas ainda podem reter alguma utilidade para testes (ex: formato do CPF, presença de e-mail).
| ID Cliente | Nome Completo | CPF | Telefone | Salário | |
|---|---|---|---|---|---|
| 101 | Maria S. | 123..-00 | ma***va@email.com | (44) 9****-1111 | [REMOVIDO] |
| 102 | João P. | 987..-99 | jo***p@provedor.net | (11) 9****-2222 | [REMOVIDO] |
| 103 | Ana C. | 111..-44 | an***ta@exemplo.org | (21) 9****-3333 | [REMOVIDO] |
Técnicas Aplicadas (Exemplo):
- Nome Completo: Mascaramento parcial (exibindo apenas o primeiro nome e a inicial do sobrenome).
- CPF: Mascaramento parcial (ocultando os dígitos centrais).
- E-mail: Mascaramento parcial (ocultando parte do nome de usuário).
- Telefone: Mascaramento parcial (ocultando parte dos dígitos do número).
- Salário: Redação/Remoção (substituindo o valor por um placeholder ou NULL).
Criptografia de Dados
Implementamos criptografia forte para proteger dados em diferentes estados:
- Em Repouso (At Rest): Dados armazenados em bancos de dados, data lakes ou arquivos são criptografados usando algoritmos robustos (ex: AES-256), garantindo que, mesmo em caso de acesso físico não autorizado ao armazenamento, os dados permaneçam ilegíveis.
- Em Trânsito (In Transit): Comunicações entre sistemas, APIs e usuários são protegidas usando protocolos seguros como TLS/SSL, garantindo a confidencialidade e a integridade dos dados durante a transferência pela rede.
Tabela: Comparação de Dados Originais e Criptografados
A tabela abaixo mostra exemplos de dados originais e como eles poderiam parecer após serem criptografados (usando AES, por exemplo) e representados em Base64. O resultado real da criptografia varia dependendo do algoritmo, modo de operação, chave e dados de inicialização.
| Campo | Dado Original (Plaintext) | Dado Criptografado (Ciphertext - Exemplo AES/Base64) |
|---|---|---|
| Nome Cliente | Maria Silva | qZ4oN9xT8rL+Jk6fW7eP0g== |
| CPF | 123.456.789-00 | A8sDfG+hJkLpQzXsVbNmYw3tFcRzEq+L |
| maria.silva@email.com | UoP5iL8kH7gD4fS2aA1qEwZxCvBnMqLp+T7yIuO0pWs= | |
| Dados Bancários | Ag: 0001, CC: 12345-6 | KjH9gFeD5cS3bA2nMyX1zQoP7lKiUtR8eW4aZsDcVfG+hJkLpQzXs= |
| Chave API | sk_live_abcdef123456xyz | M9nBvCxZlkJhGfDsApOiUyTrEwQaSdFghJkLmnBvCxZpOiUyTrEwQaMnBvCxZlkJh= |
Observações Importantes:
- Ilegibilidade: O dado criptografado é intencionalmente ilegível e não preserva o formato original.
- Chave é Essencial: Sem a chave de decriptação correta, o ciphertext é inútil. A segurança do processo depende da segurança da chave.
- Representação: A representação em Base64 (ou Hexadecimal) é comum para facilitar o manuseio do ciphertext, que é essencialmente binário.
- Diferença de Mascaramento: Enquanto o mascaramento altera ou oculta partes dos dados mantendo-os frequentemente utilizáveis para certos fins (testes, desenvolvimento) e às vezes preservando o formato, a criptografia visa a confidencialidade total, tornando os dados inutilizáveis sem a chave.
Hashing de Dados
Hashing é um processo criptográfico que transforma um conjunto de dados de qualquer tamanho (a entrada ou "mensagem") em uma sequência de caracteres de tamanho fixo, chamada de "hash", "digest" ou "checksum". Este processo é realizado por um algoritmo de hash (como SHA-256, SHA-3, ou os mais antigos e inseguros MD5 e SHA-1).
A característica fundamental do hashing é ser uma função unidirecional (one-way): é fácil calcular o hash a partir dos dados, mas é computacionalmente inviável (impossível na prática) reverter o processo para obter os dados originais a partir do hash. Isso o diferencia crucialmente da criptografia, que é bidirecional.
Os principais usos do hashing em segurança e gestão de dados são:
- Verificação de Integridade: Comparar o hash de um arquivo ou mensagem antes e depois de uma transmissão ou armazenamento permite verificar se houve alguma alteração (acidental ou maliciosa). Se os hashes forem idênticos, os dados estão íntegros.
- Armazenamento Seguro de Senhas: Sistemas não armazenam as senhas dos usuários diretamente. Em vez disso, armazenam o hash da senha combinado com um valor aleatório único por usuário (chamado "salt"). Quando o usuário faz login, o sistema calcula o hash da senha fornecida (com o mesmo salt) e compara com o hash armazenado. Isso evita que as senhas originais sejam expostas em caso de vazamento do banco de dados.
Importante: Como mencionado anteriormente, algoritmos como MD5 e SHA-1 possuem vulnerabilidades críticas e não devem ser utilizados para fins de segurança. Os padrões atuais recomendados são da família SHA-2 (SHA-256, SHA-512) ou SHA-3.
Tabela: Exemplo de Hashing
A tabela demonstra como dados originais geram hashes de tamanho fixo e como pequenas alterações nos dados resultam em hashes completamente diferentes (efeito avalanche).
| Campo | Dado Original | Hash MD5 (Exemplo - 32 hex) - NÃO SEGURO | Hash SHA-256 (Exemplo - 64 hex) - SEGURO |
|---|---|---|---|
| Nome Usuário | ana.costa | 1f67a78f6c7d8e9a0b1c2d3e4f5a6b7c | a0b1c2d3e4f5a6b7c8d9e0f1a2b3c4d5e6f7a8b9c0d1e2f3a4b5c6d7e8f9a0b1 |
| Senha | MinhaSenha#2025 | f3a2b1c0d9e8f7a6b5c4d3e2f1a0b9c8 | c1d2e3f4a5b6c7d8e9f0a1b2c3d4e5f6a7b8c9d0e1f2a3b4c5d6e7f8a9b0c1d2 |
| Senha | minhasenha#2025 | 9e8f7a6b5c4d3e2f1a0b9c8f3a2b1c0d | d2e3f4a5b6c7d8e9f0a1b2c3d4e5f6a7b8c9d0e1f2a3b4c5d6e7f8a9b0c1d2e3 |
| Arquivo TXT | "Conteúdo do arquivo." | a7b8c9d0e1f2a3b4c5d6e7f8a9b0c1d2 | e3f4a5b6c7d8e9f0a1b2c3d4e5f6a7b8c9d0e1f2a3b4c5d6e7f8a9b0c1d2e3f4 |
Note como a simples mudança de "M" para "m" na senha gerou hashes completamente diferentes, e como os hashes têm sempre o mesmo comprimento para um dado algoritmo (32 hex para MD5, 64 hex para SHA-256).
Para senhas em SQL, sempre use um SALT. A lógica de gerar salt, combinar com a senha e verificar geralmente é feita na camada de aplicação (Python, Java, etc.).
Salt
A Importância do Salt no Hashing de Senhas
Como mencionado, um dos principais usos do hashing é o armazenamento seguro de senhas. No entanto, simplesmente aplicar hash a uma senha (como nos exemplos hash_sha256(senha_original)) não é suficiente. Se dois usuários tiverem a mesma senha, eles terão o mesmo hash armazenado, e atacantes podem usar tabelas pré-computadas de hashes comuns (chamadas "rainbow tables") para descobrir as senhas originais.
Para mitigar isso, utiliza-se um "Salt":
- O que é: Um valor aleatório e único gerado para cada senha de usuário no momento do cadastro.
- Como é usado: O salt é combinado com a senha original antes de aplicar a função de hash. Por exemplo: hash_resultado = hash_sha256(senha_original + salt_unico_do_usuario).
- Armazenamento: O salt não é secreto e é armazenado no banco de dados junto com o hash resultante da senha+salt.
- Verificação: Quando o usuário tenta fazer login, o sistema recupera o salt armazenado para aquele usuário, combina-o com a senha fornecida, calcula o hash e compara o resultado com o hash armazenado.
- Benefício: Mesmo que dois usuários usem a mesma senha, seus salts serão diferentes, resultando em hashes armazenados completamente diferentes. Isso torna as rainbow tables ineficazes.
Recomendação: Em vez de implementar a lógica de salt e hash manualmente, use bibliotecas de mercado robustas e testadas (como passlib ou bcrypt em Python) que cuidam de gerar salts seguros, aplicar algoritmos de hash fortes com múltiplas iterações e realizar a verificação de forma correta.
Tabela Comparativa: Mascaramento vs Criptografia vs Hashing
Para consolidar o entendimento, a tabela abaixo resume as principais características e diferenças entre as três técnicas abordadas:
| Característica | Mascaramento | Criptografia | Hashing |
|---|---|---|---|
| Objetivo | Ocultar dados parcialmente | Proteger confidencialidade | Verificar integridade; senhas |
| Reversível | ❌ Não | ✅ com chave correta | ❌ Não |
| Resultado | Dados ofuscados | Ilegível, formato diferente | Hash fixo, ilegível |
| Precisa de chave | ❌ Não | ✅ para en/decriptação | ❌ Não |
| Uso comum | Anonimização parcial | Proteção de dados em trânsito/repouso | Verificação, senhas, checksums |
| Confidencialidade | ❌ Reduz exposição | ✅ Com chave segura | ❌ Não |
| Integridade | ❌ Não | ✅ Com AEAD/Autenticação | ✅ Principal foco |
| Exemplo | ***.***.123-45 | qZ4oN9xT8rL+Jk6fW7eP0g== | a0b1c2d3e4... |
Esta tabela ajuda a escolher a técnica mais adequada dependendo do requisito específico de segurança ou privacidade em cada cenário dentro dos projetos da DB1.
A aplicação dessas técnicas é integrada aos nossos pipelines de dados e plataformas, assegurando que a proteção seja consistente e automatizada sempre que possível.
Gestão de Logs
A Gestão de Logs é crucial para a rastreabilidade, auditoria e monitoramento de segurança. Implementamos um sistema centralizado e padronizado para coletar, armazenar e analisar logs de eventos relevantes de nossos sistemas e aplicações de dados.
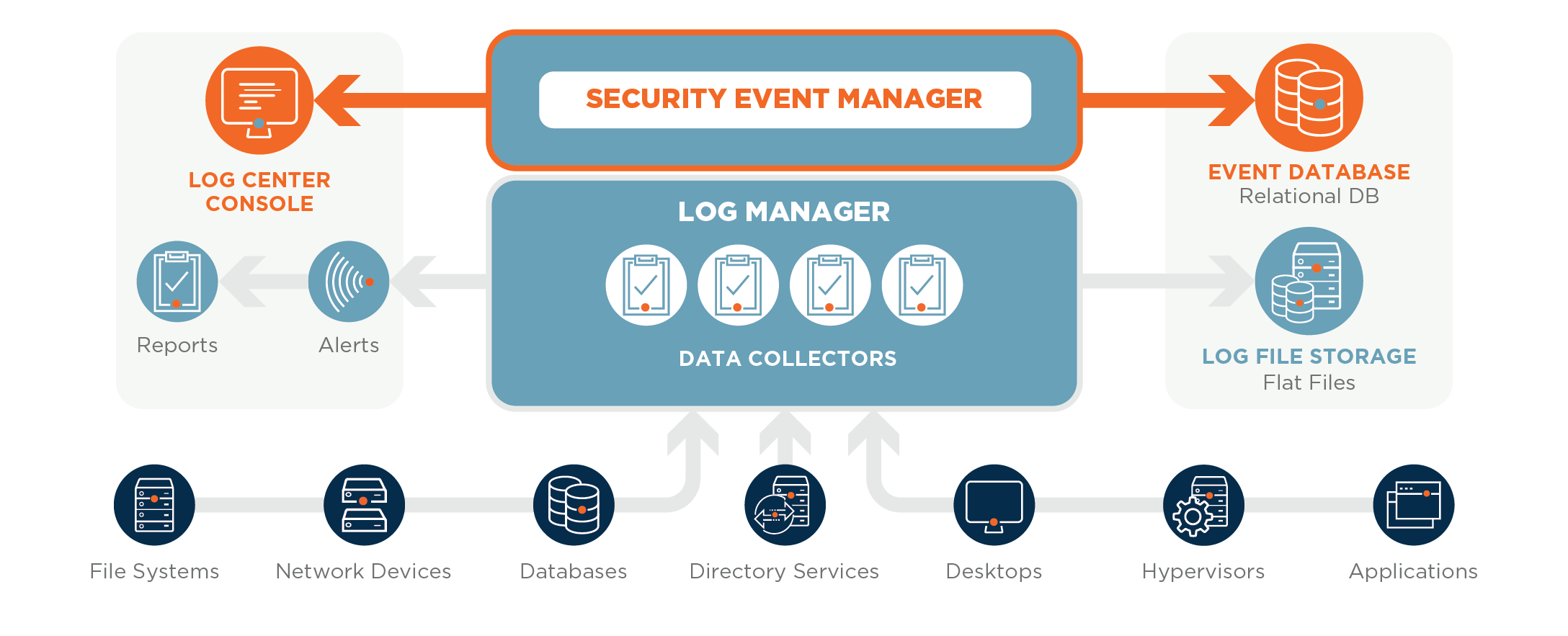
Nossas práticas incluem:
- Coleta Abrangente: Registramos eventos chave, como tentativas de acesso (bem-sucedidas e falhas), modificações em dados críticos, alterações de configuração, execução de processos e erros de sistema.
- Padronização de Formato: Utilizamos formatos estruturados (ex: JSON) para facilitar a análise automatizada e a correlação de eventos entre diferentes fontes.
- Armazenamento Seguro e Retenção Adequada: Os logs são armazenados em repositórios seguros, com controle de acesso restrito e políticas de retenção definidas (conforme descrito na seção seguinte) para cumprir requisitos legais e de auditoria.
- Monitoramento e Alertas: Ferramentas como o ELK Stack (Elasticsearch, Logstash, Kibana), Splunk ou soluções nativas de nuvem (AWS CloudWatch Logs, Azure Monitor Logs) são usadas para monitorar logs em tempo real, identificar atividades suspeitas e gerar alertas para a equipe de segurança.
Uma gestão eficaz de logs nos permite investigar incidentes, comprovar conformidade, detectar anomalias de segurança e otimizar o desempenho dos sistemas.
Política de Retenção
Definir por quanto tempo os dados devem ser mantidos e quando devem ser descartados de forma segura é essencial para a compliance e a gestão eficiente de recursos. Nossa Política de Retenção de Dados estabelece diretrizes claras para o ciclo de vida da informação, desde a criação até o expurgo.
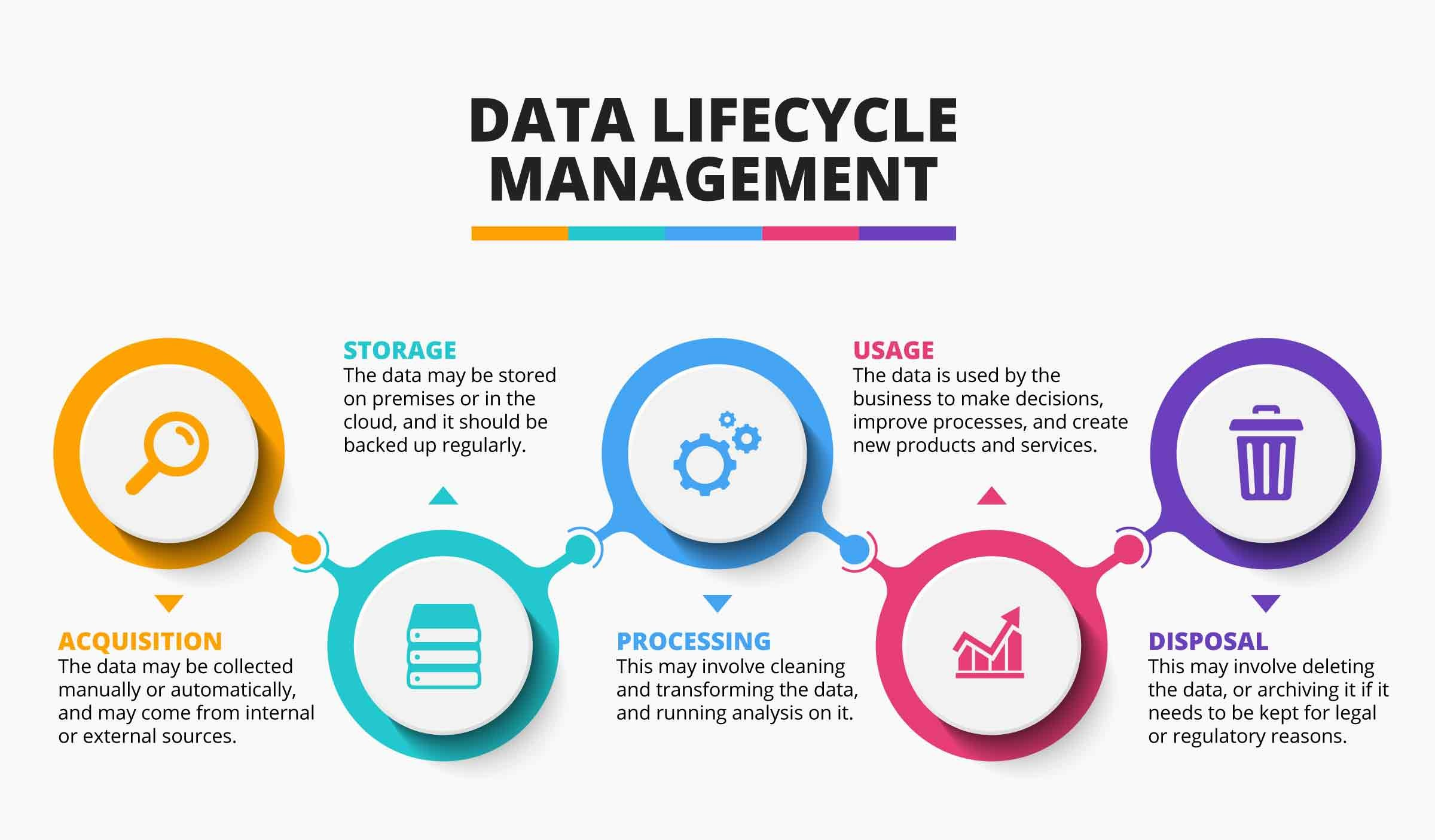
Principais aspectos da nossa política:
- Classificação de Dados: A retenção é definida com base na classificação dos dados (ex: dados pessoais, financeiros, operacionais, logs) e nos requisitos legais, regulatórios ou contratuais aplicáveis a cada categoria.
- Períodos de Retenção: Estabelecemos períodos mínimos e máximos de retenção para cada tipo de dado, equilibrando a necessidade de acesso histórico com os princípios de minimização de dados da LGPD/GDPR.
- Processos de Arquivamento e Expurgo: Definimos procedimentos seguros para arquivar dados que precisam ser mantidos por longos períodos (mas não em acesso ativo) e para o expurgo definitivo (deleção segura ou anonimização) de dados que atingiram o fim de seu ciclo de vida.
- Automação e Auditoria: Implementamos, sempre que possível, processos automatizados para aplicar as regras de retenção e realizamos auditorias periódicas para garantir a conformidade com a política.
Uma política de retenção bem definida ajuda a reduzir riscos legais, otimizar custos de armazenamento e garantir que apenas dados necessários e relevantes sejam mantidos.
Gestão de Identidade e Acesso (IAM)
A Gestão de Identidade e Acesso (IAM) é fundamental para garantir que apenas usuários autorizados tenham acesso aos recursos de dados apropriados, com base em suas funções e responsabilidades. Aplicamos rigorosamente o Princípio do Menor Privilégio.
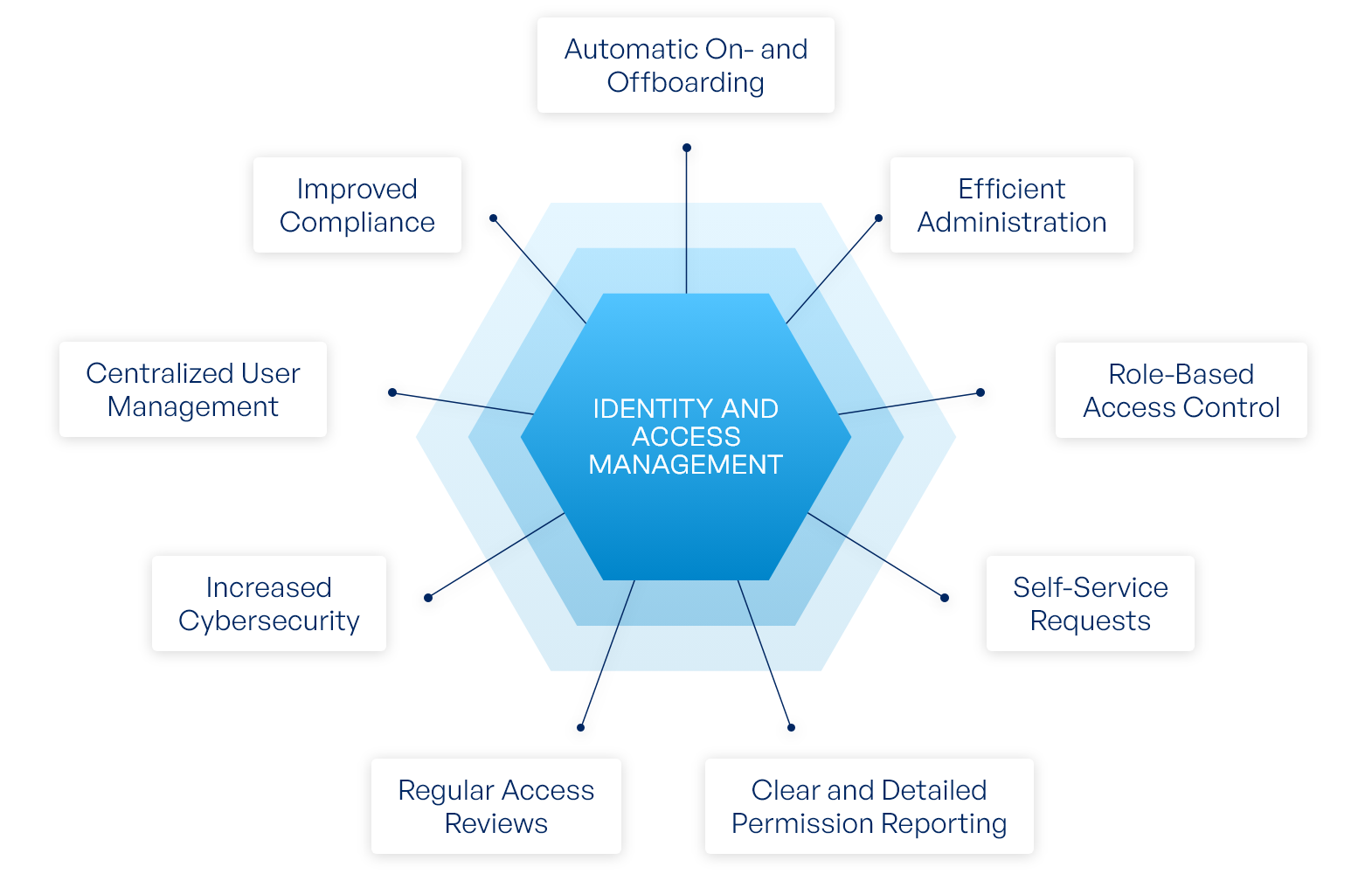
Nossa abordagem de IAM inclui:
- Autenticação Forte: Utilizamos mecanismos robustos de autenticação, incluindo integração com diretórios corporativos via Single Sign-On (SSO) e, quando aplicável, Autenticação Multifator (MFA) para acesso a sistemas e dados críticos.
- Controle de Acesso Baseado em Função (RBAC): Predominantemente, utilizamos o modelo RBAC, onde as permissões são atribuídas a funções (ex: Analista de Dados, Engenheiro de Dados, Administrador de Segurança) e os usuários são associados a essas funções. Isso simplifica a gestão e garante consistência.
- Controle de Acesso Baseado em Atributos (ABAC): Em cenários mais complexos, podemos complementar o RBAC com ABAC, onde as permissões são concedidas com base em atributos do usuário (ex: departamento, projeto), do recurso (ex: classificação do dado) e do ambiente (ex: localização da rede).
- Ferramentas Centralizadas: Utilizamos serviços como AWS IAM, Azure Active Directory (Azure AD) ou outras ferramentas de IAM para gerenciar identidades, políticas e permissões de forma centralizada e auditável.
- Revisões Periódicas de Acesso: Realizamos revisões regulares das permissões concedidas para garantir que continuem adequadas e remover acessos desnecessários ou obsoletos.
- Processos de Solicitação e Aprovação: Implementamos workflows claros (ex: via Jira, ServiceNow) para solicitação, aprovação e revogação de acessos, garantindo rastreabilidade.
Uma IAM eficaz é crucial para prevenir vazamentos de dados, garantir a segregação de funções e atender aos requisitos de auditoria e conformidade.
Plano de Resposta a Incidentes de Dados
Mesmo com as melhores práticas de segurança e governança, incidentes de dados (como vazamentos, corrupção de dados ou falhas críticas de sistemas) podem ocorrer. Na DB1, possuímos um Plano de Resposta a Incidentes de Dados estruturado para detectar, conter, erradicar e recuperar-se de tais eventos de forma rápida e eficaz, minimizando o impacto nos negócios e mantendo a confiança dos stakeholders.
Nosso plano segue etapas bem definidas, alinhadas com frameworks como o do NIST (National Institute of Standards and Technology):
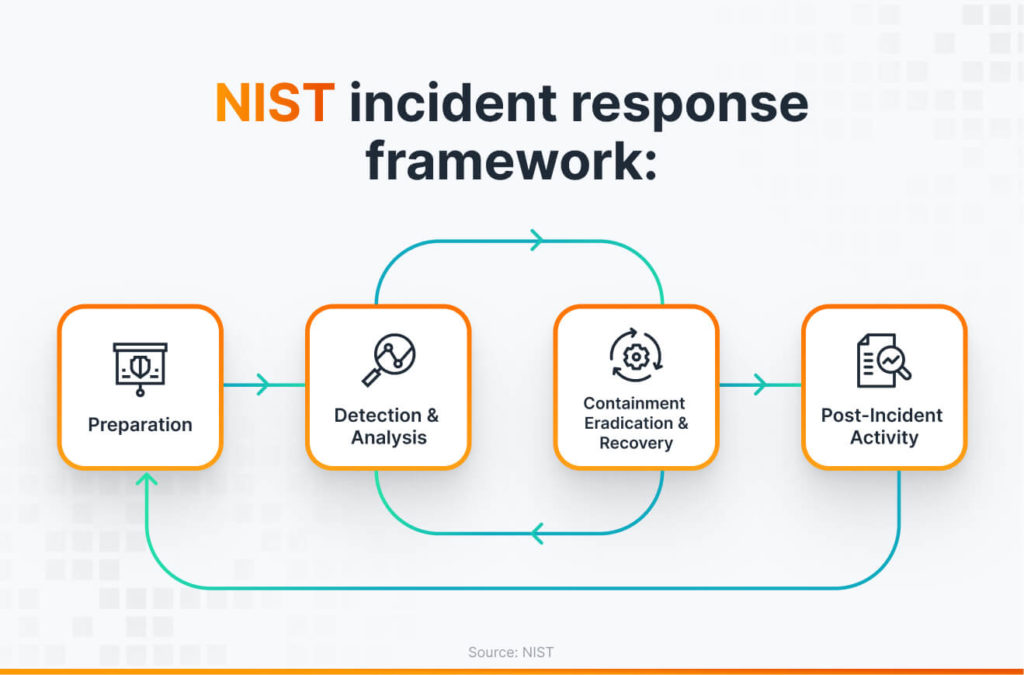
1. Preparação
- Definição de papéis e responsabilidades (Equipe de Resposta a Incidentes).
- Desenvolvimento de playbooks para cenários comuns (vazamento de
PII, ataque de ransomware, falha de pipeline crítico). - Treinamento regular das equipes envolvidas.
- Manutenção de ferramentas e contatos necessários (comunicação, forense, jurídico).
2. Detecção e Análise
- Monitoramento contínuo (logs, métricas, alertas - vide Observabilidade e Monitoramento) para identificar atividades suspeitas ou anômalas.
- Análise inicial para determinar a natureza, escopo e severidade do incidente.
- Ativação da Equipe de Resposta a Incidentes e canais de comunicação seguros.
3. Contenção
- Isolar os sistemas afetados para prevenir a propagação do incidente.
- Bloquear acessos não autorizados.
- Preservar evidências para análise forense.
4. Erradicação
- Identificar e eliminar a causa raiz do incidente (ex: remover malware, corrigir vulnerabilidade, revogar credenciais comprometidas).
- Validar que a ameaça foi completamente removida.
5. Recuperação
- Restaurar os sistemas e dados afetados a partir de backups seguros.
- Validar a integridade e funcionalidade dos sistemas restaurados.
- Monitorar de perto para garantir que o incidente não se repita.
6. Pós-Incidente (Lições Aprendidas)
- Realizar uma análise post-mortem detalhada para entender o que aconteceu, como a resposta funcionou e o que pode ser melhorado.
- Atualizar políticas, procedimentos e controles de segurança.
- Comunicar o incidente (internamente e, se necessário, externamente para clientes e reguladores, conforme exigido pela LGPD/GDPR).
Alertas automatizados provenientes de nossas ferramentas de Monitoramento e Observabilidade são cruciais para a detecção precoce, enquanto playbooks pré-definidos agilizam a mitigação rápida. Um plano de resposta a incidentes bem ensaiado e mantido é vital para a resiliência operacional e a gestão de riscos na DB1.
Práticas de Desenvolvimento Seguro para Dados (Secure Data Development Lifecycle)
Na DB1, a segurança é um pilar fundamental não apenas no desenvolvimento de software tradicional, mas especificamente no ciclo de vida de criação e manutenção de pipelines de dados, modelos analíticos e da infraestrutura de dados associada. Adotamos a filosofia de "shift-left security" também neste contexto, integrando verificações e práticas de segurança desde as fases iniciais para construir fluxos de dados e soluções analíticas que sejam seguras por design. Nossas práticas incluem:
Modelagem de Ameaças para Fluxos de Dados
Análise proativa de potenciais riscos de segurança em cada etapa de uma pipeline de dados (ingestão, transformação, armazenamento, consumo), identificando ameaças como acesso indevido, corrupção de dados, exfiltração de informações sensíveis ou negação de serviço.
Revisão de Código e Configuração Segura
Análise cuidadosa de código (ex: Python, SQL, Spark), scripts de orquestração (DAGs), notebooks de análise e definições de Infraestrutura como Código (IaC). O foco é identificar falhas como segredos expostos (hardcoded secrets), permissões excessivas em contas de serviço, lógica de transformação que possa expor dados sensíveis e configurações inseguras de recursos de dados (buckets, bancos de dados, data warehouses).
Gestão Segura de Segredos
Utilização de cofres de segredos (como AWS Secrets Manager, Azure Key Vault, HashiCorp Vault) para armazenar e injetar de forma segura credenciais, chaves de API e outros segredos necessários para a execução das pipelines, evitando que sejam expostos no código ou em logs.
Análise de Dependências (SCA) para Bibliotecas de Dados
Verificação automatizada de vulnerabilidades conhecidas nas bibliotecas e pacotes utilizados nos projetos de dados, incluindo aquelas específicas para manipulação, processamento e análise de dados (ex: Pandas, PySpark, Dask).
Validação e Testes de Segurança de Dados
Implementação de testes automatizados que não só garantem a qualidade e a integridade dos dados, mas também ajudam a prevenir vulnerabilidades, como injeção de código malicioso através de fontes de dados não confiáveis. Uso de ferramentas de varredura de segurança integradas aos pipelines de CI/CD para análise estática do código e das configurações de infraestrutura.
Aplicação do Princípio do Menor Privilégio em Pipelines
Garantir que as contas de serviço, roles ou usuários utilizados para executar pipelines de dados tenham apenas as permissões estritamente necessárias para realizar suas tarefas em cada ambiente (desenvolvimento, homologação, produção).
Treinamento Específico para Times de Dados
Capacitação contínua das equipes de engenharia e análise de dados sobre práticas seguras de manipulação de dados (incluindo anonimização/mascaramento quando aplicável), requisitos de privacidade (LGPD/GDPR) e desenvolvimento seguro para as plataformas e ferramentas de dados utilizadas.
Ao incorporar a segurança em cada etapa do ciclo de vida dos dados, garantimos a integridade, confidencialidade e resiliência dos nossos fluxos de dados, das plataformas que os suportam e das informações valiosas que eles contêm, protegendo a DB1 e seus clientes desde a concepção da solução.
Prevenção de Perda de Dados (Data Loss Prevention - DLP)
Para complementar nossas outras camadas de segurança, implementamos controles e tecnologias de Prevenção de Perda de Dados (DLP). O objetivo do DLP é monitorar, detectar e prevenir ativamente a transferência não autorizada ou o vazamento acidental de informações confidenciais e sensíveis (como dados de clientes, propriedade intelectual, informações financeiras) para fora dos ambientes controlados e seguros da DB1.
Nossas estratégias de DLP podem incluir:
- Monitoramento de Endpoints: Controles aplicados em estações de trabalho para gerenciar o uso de dispositivos de armazenamento externo e a cópia de dados sensíveis.
- Análise de Tráfego de Rede e E-mail: Inspeção de comunicações para identificar e bloquear ou alertar sobre o envio de informações classificadas como confidenciais para destinos não autorizados.
- Controles em Aplicações Cloud: Configuração de políticas em serviços de nuvem para prevenir o compartilhamento inadequado ou a exposição pública de dados sensíveis.
A implementação de DLP é um controle proativo crucial para minimizar o risco de violações de dados e garantir a conformidade contínua com regulamentações como a LGPD e o GDPR, protegendo tanto a DB1 quanto seus clientes.
Auditorias e Certificações
O compromisso da DB1 com a segurança e a conformidade é validado através de auditorias regulares e pela busca contínua de aderência a padrões e certificações reconhecidos pelo mercado. Entendemos que a validação externa e interna é fundamental para garantir a eficácia dos nossos controles e para fornecer transparência e segurança aos nossos clientes.
Nossas iniciativas nesta área incluem:
- Auditorias Internas: Revisões periódicas dos nossos processos, políticas e controles de segurança e compliance para identificar áreas de melhoria e garantir a conformidade contínua.
- Auditorias Externas e Certificações: Buscamos e mantemos certificações como ISO 27001 (Gestão de Segurança da Informação), que atestam a maturidade dos nossos controles relacionados à segurança, disponibilidade, integridade de processamento, confidencialidade e privacidade.
- Avaliações de Conformidade Regulatória: Verificações específicas para garantir o alinhamento com legislações como LGPD e GDPR.
Essas auditorias e certificações não são apenas selos de aprovação; elas representam um compromisso contínuo com a excelência em segurança e fornecem aos nossos clientes e parceiros a confiança de que suas informações estão sendo gerenciadas de acordo com as melhores práticas internacionais.
Gestão de Risco de Terceiros
Reconhecemos que o ecossistema tecnológico moderno frequentemente envolve a utilização de ferramentas, plataformas e serviços de terceiros. A segurança da nossa cadeia de suprimentos digitais é, portanto, uma extensão crítica da nossa própria postura de segurança. Na DB1, implementamos um processo de Gestão de Risco de Terceiros para avaliar e gerenciar os riscos associados a fornecedores que possam processar, armazenar ou ter acesso a dados da empresa ou de nossos clientes.
Nossas práticas incluem:
- Avaliação de Segurança (Due Diligence): Análise da postura de segurança de potenciais fornecedores antes da contratação, utilizando questionários de segurança, revisão de suas certificações (como ISO 27001) e análise de suas políticas de privacidade e segurança.
- Cláusulas Contratuais: Inclusão de requisitos claros de segurança, privacidade e conformidade (incluindo LGPD/GDPR) nos contratos com fornecedores.
- Monitoramento Contínuo (quando aplicável): Acompanhamento da performance de segurança de fornecedores críticos ao longo do relacionamento.
- Plano de Resposta Coordenado: Definição de procedimentos para lidar com incidentes de segurança que possam ocorrer em ambientes de terceiros, mas que afetem dados sob nossa responsabilidade.
Ao gerenciar ativamente os riscos associados a terceiros, garantimos que nossos parceiros mantenham um nível de segurança compatível com os padrões da DB1, protegendo assim todo o ecossistema do projeto e os dados confiados a nós.
Em resumo, na DB1, Segurança e Compliance são componentes fundamentais da nossa cultura de dados, aplicados de forma transversal em todos os nossos projetos e internamente. Não se tratam apenas de diretrizes teóricas, mas de práticas ativamente implementadas e monitoradas para garantir a proteção robusta dos ativos de informação e a conformidade regulatória.
Através da implementação rigorosa de técnicas como mascaramento e criptografia para proteção de dados sensíveis, gestão de identidade e acesso (IAM) baseada no princípio do menor privilégio, monitoramento e gestão detalhada de logs para assegurar rastreabilidade e auditoria, políticas claras de retenção para gerenciar o ciclo de vida dos dados, e um plano de resposta a incidentes bem estruturado e ensaiado, garantimos não apenas a conformidade com regulamentações essenciais como LGPD e GDPR, mas também a resiliência operacional necessária no ambiente digital atual.
Este compromisso com a segurança e a conformidade é essencial para proteger os ativos de informação dos nossos clientes, mitigar riscos e fortalecer a base de confiança em cada solução e projeto que a DB1 entrega.
Créditos: