Processamento de Dados
Na DB1, o processamento de dados vai além da movimentação de informações entre sistemas — é um processo estruturado, eficiente e resiliente, que transforma dados brutos em ativos confiáveis e prontos para análise. Investimos em boas práticas, automação e monitoramento para garantir que nossos pipelines sejam escaláveis, observáveis e alinhados às necessidades do negócio.
Nosso modelo de processamento é pensado para garantir performance, rastreabilidade e modularidade, promovendo agilidade sem abrir mão da robustez. A seguir, destacamos os pilares que sustentam essa abordagem.
Pipelines Eficientes
Desenvolver pipelines de ingestão, transformação e carga (ETL/ELT) escaláveis e otimizados é uma das principais prioridades no ciclo de vida dos dados.
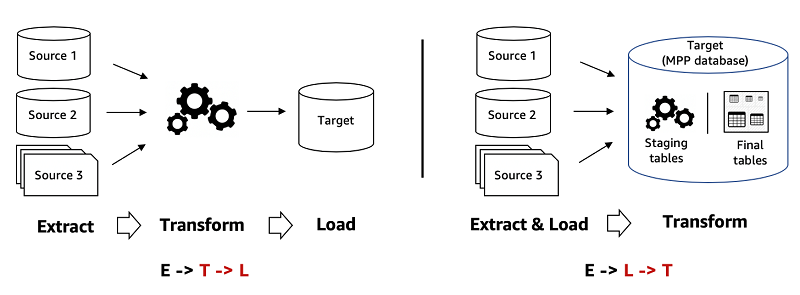
Adotamos práticas que garantem:
- Escalabilidade Horizontal e Vertical: Arquiteturas distribuídas e uso eficiente de recursos computacionais.
- Paralelismo e Particionamento: Divisão de cargas em múltiplas execuções simultâneas para ganho de performance.
- Orquestração Inteligente: Utilização de ferramentas como Apache Airflow, dbt, AWS Step Functions e Azure Data Factory para coordenar e monitorar processos de forma confiável.
- Reprocessamento Seguro: Capacidade de reexecutar etapas específicas sem corromper ou duplicar dados.
- Ambientes Modulares e Reutilizáveis: Estruturação do código em módulos reutilizáveis que facilitam manutenção e versionamento.
Essas práticas nos permitem construir pipelines que respondem rapidamente às mudanças, lidam bem com grandes volumes e oferecem rastreabilidade em cada etapa.
Arquiteturas de Processamento
A escolha da arquitetura adequada para o processamento depende do tipo de dado, latência necessária e volume envolvido. Trabalhamos com diferentes modelos, como:
- Batch Processing: Ideal para grandes volumes com baixa necessidade de latência, utilizando ferramentas como Apache Spark, Glue, BigQuery e Snowflake.
- Stream Processing: Para dados em tempo real, utilizamos ferramentas como Kafka, Flink e Kinesis.
- Lambda Architecture: Combina batch e streaming para cenários que exigem tanto histórico quanto eventos em tempo real.
- ELT-First Approach: Sempre que possível, priorizamos a extração e carga brutas antes da transformação, aproveitando o poder de processamento do data warehouse.
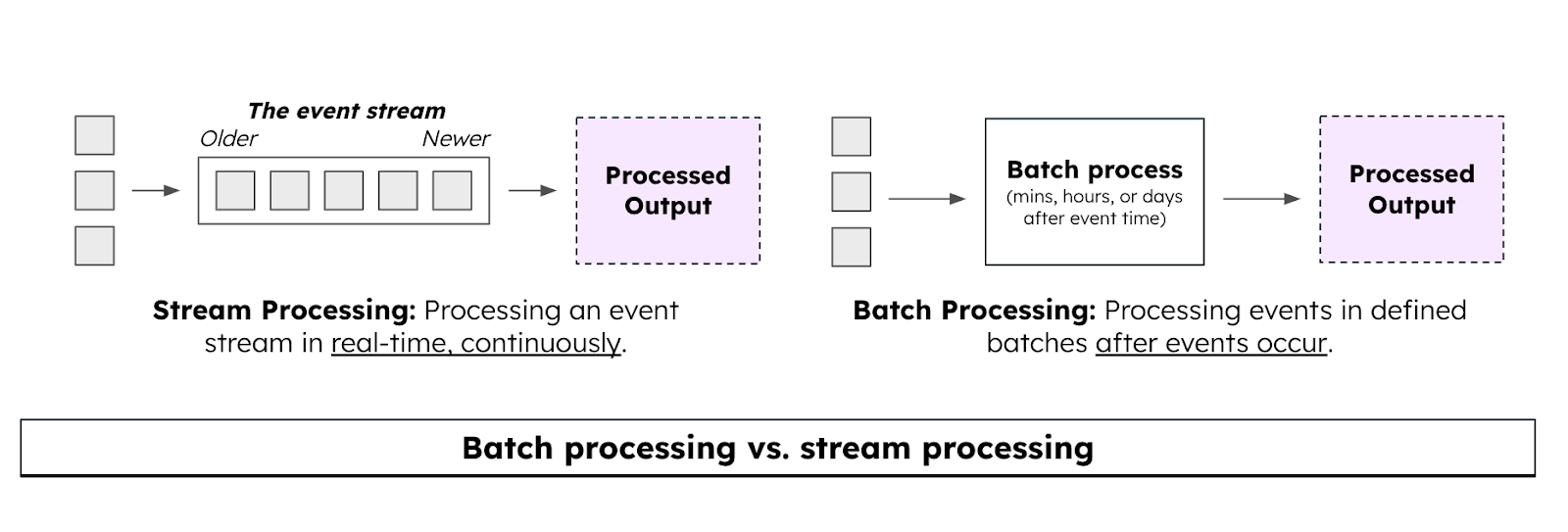
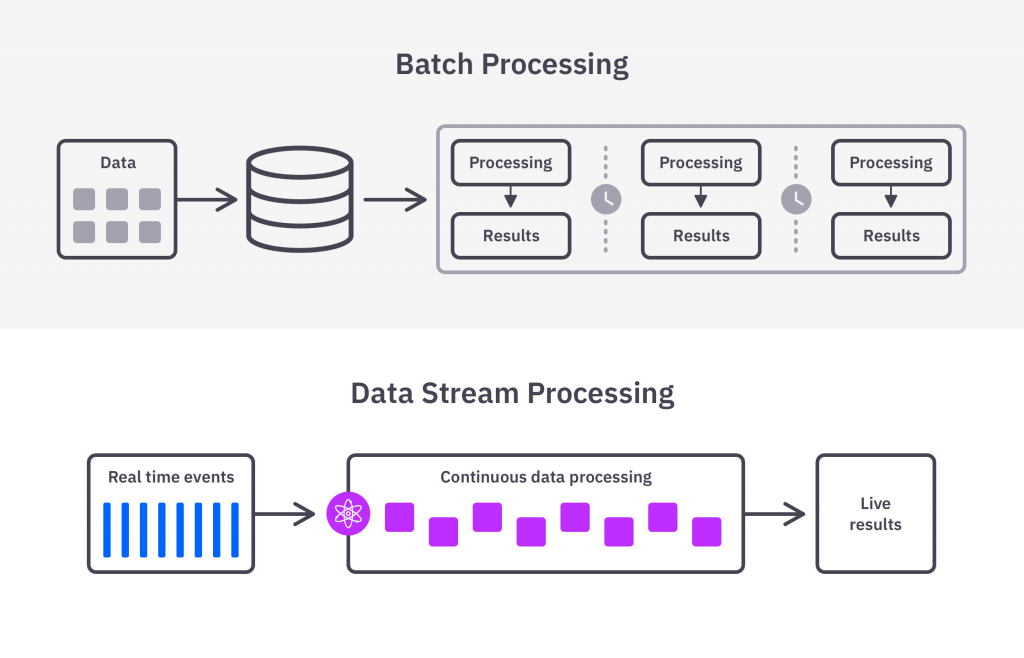
Essa flexibilidade nos permite adaptar a arquitetura ao contexto do projeto, sempre com foco em eficiência e governança.
Processamento Distribuído Big Data
Para lidar com grandes volumes de dados com eficiência e escalabilidade, utilizamos arquiteturas de processamento distribuído baseadas em tecnologias consolidadas de Big Data.
Adotamos engines como Apache Spark, Apache Flink e serviços gerenciados como AWS EMR, Databricks e Google Dataflow, que permitem processar conjuntos massivos de dados de forma paralela, resiliente e com alta performance.
Entre os principais benefícios dessa abordagem, destacamos:
- Escalabilidade Horizontal: Processamento em clusters, com alocação dinâmica de recursos conforme a carga.
- Alto Desempenho: Otimizações como execução in-memory, paralelismo e particionamento inteligente dos dados.
- Suporte a Diversos Formatos e Fontes: Leitura e escrita em múltiplos formatos (Parquet, Avro, ORC, JSON, etc.) e integração com bancos relacionais, NoSQL e data lakes.
- Tolerância a Falhas: Execução resiliente com recuperação automática de jobs em caso de falhas de nós.
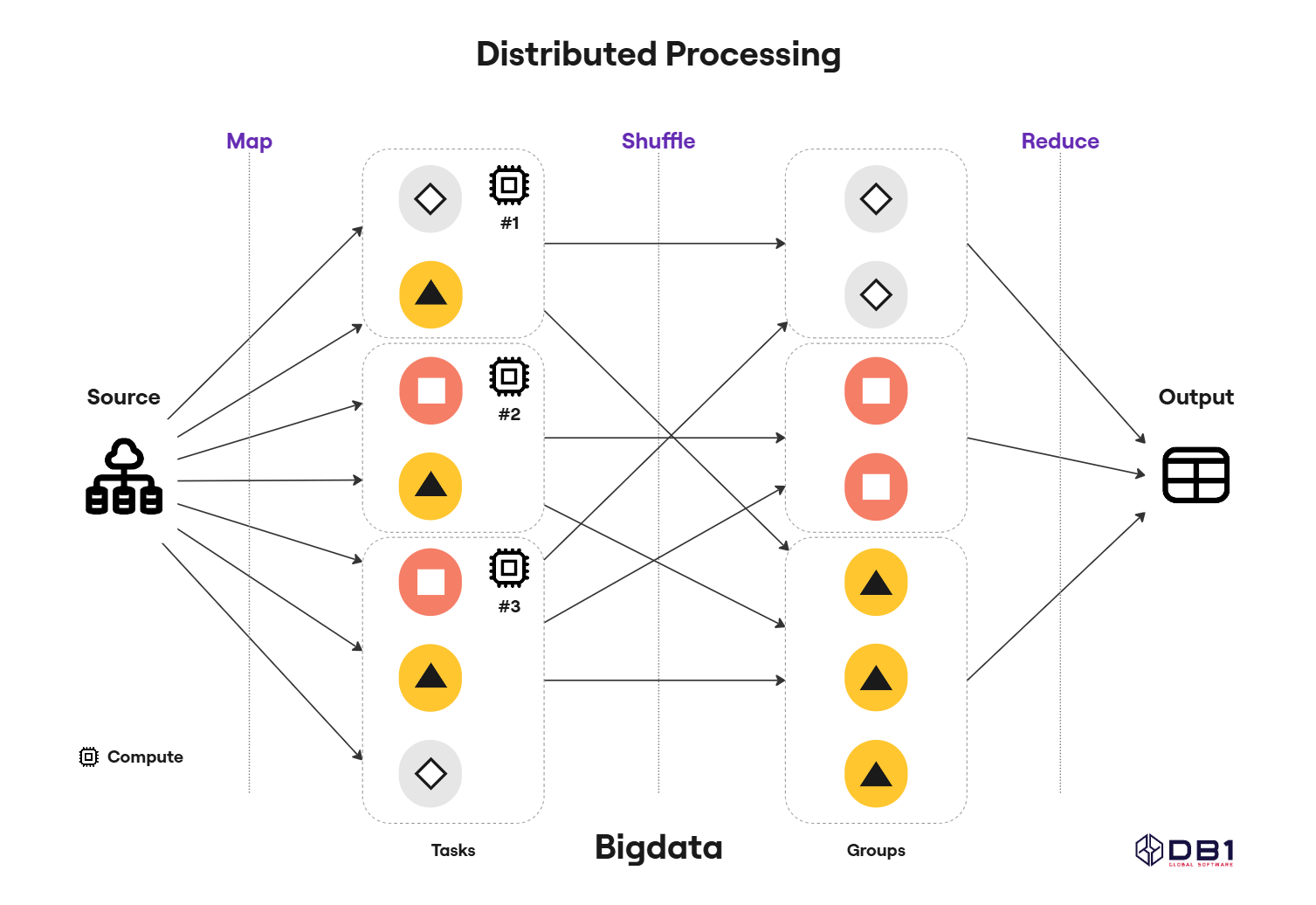
Utilizamos esse modelo tanto para cargas batch quanto para processamento em tempo real (streaming), dependendo do contexto do negócio. Com isso, garantimos que os dados estejam disponíveis de forma rápida, confiável e com capacidade de escalar conforme a demanda.
O processamento distribuído é um dos pilares que sustentam nossas pipelines em ambientes de Big Data, viabilizando análises complexas e tomadas de decisão em larga escala.
Modularidade e Reutilização
Promovemos a componentização das pipelines, evitando retrabalho e incentivando a padronização:
- Templates Reutilizáveis: Blocos de código prontos para tarefas comuns como leitura de APIs, transformação de dados tabulares, tratamento de erros, etc.
- Catálogo de Componentes: Repositório central de componentes testados e aprovados.
- Abordagem Declarativa com dbt: Modelagem de transformações em SQL modular, versionado e validado.
Com isso, reduzimos o tempo de desenvolvimento, aumentamos a confiabilidade e facilitamos a manutenção das soluções.
Gestão de Erros e Logs
Erros são inevitáveis — o que muda é como lidamos com eles. Nossas pipelines são projetadas com:
- Tratamento Estruturado de Falhas: Capacidade de isolar e reportar falhas sem interromper toda a execução.
- Logs Padronizados: Registros estruturados por etapa, com níveis de severidade e contexto completo.
- Notificações Automatizadas: Alertas em canais como Slack ou Teams para incidentes críticos.
Essa abordagem garante rápida resposta e diagnóstico de falhas, minimizando impactos nos consumidores de dados.
Versionamento e Deploy Automatizado com DataOps
Adotamos práticas de DataOps para trazer agilidade, qualidade e confiabilidade aos nossos processos de dados, aplicando os mesmos princípios de DevOps ao ciclo de vida dos dados.
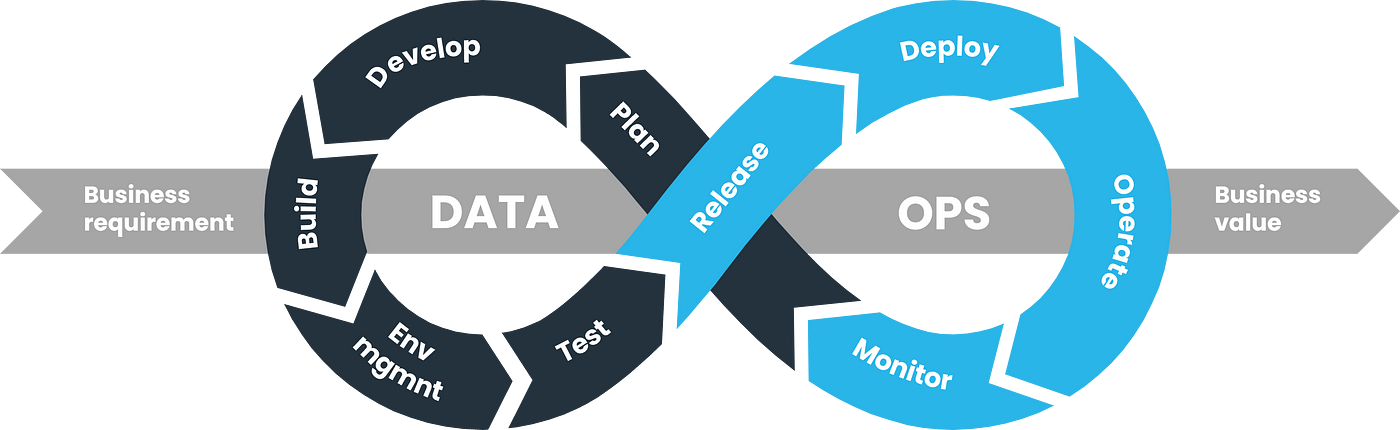
Trabalhamos com integração e entrega contínua (CI/CD) para dados, garantindo que qualquer alteração em código, pipelines ou configurações seja versionada, validada e implantada de forma segura e rastreável. Nossos processos incluem:
- Controle de versão via Git para todo o código de transformação, testes e configurações;
- Pipelines de CI que executam validações automáticas, testes (unitários e de dados), linting e verificações de qualidade antes de qualquer deploy;
- Deploy automatizado para múltiplos ambientes (dev, staging, prod), com rastreabilidade completa e rollback seguro quando necessário.
Essa abordagem permite:
- Redução de erros humanos e inconsistências entre ambientes;
- Entregas frequentes e seguras de novas funcionalidades ou ajustes;
- Rastreabilidade e governança sobre todas as alterações nos dados.
Com DataOps, garantimos um fluxo contínuo e confiável desde o desenvolvimento até a produção, alinhando velocidade e controle na entrega de valor com dados.
O processamento de dados na DB1 é sustentado por princípios de eficiência, modularidade e confiabilidade, integrando boas práticas de engenharia com as exigências de governança e segurança.
Nos próximos tópicos, detalharemos práticas como observabilidade aplicada ao processamento, tratamento de dados sensíveis, otimizações de performance e gestão de custos em pipelines.
Créditos: